[Completed] Professional Google Cybersecurity Specialization C6/8; Sound the Alarm: Detection and Response
- Introduction to Course 6
- Terms and definitions from the certificate
- Dave: Grow your cybersecurity career with mentors
- Welcome to week 1
- Introduction to the incident response lifecycle
- Incident response teams
- Fatima: The importance of communication during incident response
- Roles in response
- Incident response plans
- Incident response tools
- The value of documentation
- Intrusion detection systems
- Overview of detection tools
- Alert and event management with SIEM and SOAR tools
- Wrap-up; Terms and definitions from Course 6, Week 1
- Welcome to week 2
- Casey: Apply soft skills in cybersecurity
- The importance of network traffic flows
- Maintain awareness with network monitoring
- Data exfiltration attacks
- Packets and packet captures
- Learn more about packet captures
- Interpret network communications with packets
- Reexamine the fields of a packet header
- Investigate packet details
- Packet captures with tcpdump
- example tcp dump activity
- Activity: Research network protocol analyzers
- Wrap-up; Terms and definitions from Course 6, Module 2
- Welcome to module 3 ; The detection and analysis phase of the lifecycle
- Cybersecurity incident detection methods
- MK: Changes in the cybersecurity industry
- Indicators of compromise
- Analyze indicators of compromise with investigative tools
- Analyze indicators of compromise with investigative tools
- The benefits of documentation
- Document evidence with chain of custody forms
- Best practices for effective documentation
- The value of cybersecurity playbooks
- Generic Phishing Playbook Version 1.0
- The role of triage in incident response
- Robin: Foster cross-team collaboration
- The triage process
- The containment, eradication, and recovery phase of the lifecycle
- Business continuity considerations
- The post-incident activity phase of the lifecycle
- Post-incident review
- Wrap-up; Terms and definitions from Course 6, Module 3
- read
- Welcome to module 4
- The importance of logs
- The importance of logs
- Best practices for log collection and management
- Rebecca: Learn new tools and technologies
- Variations of logs
- Overview of log file formats
- Security monitoring with detection tools
- Detection tools and techniques
- Grace: Security mindset in detection and response
- Components of a detection signature
- Examine signatures with Suricata
- Examine signatures with Suricata
- Examine Suricata logs
- Overview of Suricata
- Activity: Explore signatures and logs with Suricata
- Reexamine SIEM tools
- Log sources and log ingestion
- Query for events with Splunk
- Search methods with SIEM tools
- Follow-along guide for Splunk sign-up
- Wrap-up; Glossary terms from module 4
- Course wrap-up
- Terms and definitions from Course 6, course 6 glossary
Introduction to Course 6
Terms and definitions from the certificate
Google Cybersecurity Certificate glossary from: "Sound the Alarm: Detection and Response; part 6 of 8 in the professional Cybersecurity cert"
A
Absolute file path: The full file path, which starts from the root
Access controls: Security controls that manage access, authorization, and accountability of information
Active packet sniffing: A type of attack where data packets are manipulated in transit
Address Resolution Protocol (ARP): A network protocol used to determine the MAC address of the next router or device on the path
Advanced persistent threat (APT): An instance when a threat actor maintains unauthorized access to a system for an extended period of time
Adversarial artificial intelligence (AI): A technique that manipulates artificial intelligence (AI) and machine learning (ML) technology to conduct attacks more efficiently
Adware: A type of legitimate software that is sometimes used to display digital advertisements in applications
Algorithm: A set of rules used to solve a problem
Analysis: The investigation and validation of alerts
Angler phishing: A technique where attackers impersonate customer service representatives on social media
Anomaly-based analysis: A detection method that identifies abnormal behavior
Antivirus software: A software program used to prevent, detect, and eliminate malware and viruses
Application: A program that performs a specific task
Application programming interface (API) token: A small block of encrypted code that contains information about a user
Argument (Linux): Specific information needed by a command
Argument (Python): The data brought into a function when it is called
Array: A data type that stores data in a comma-separated ordered list
Assess: The fifth step of the NIST RMF that means to determine if established controls are implemented correctly
Asset: An item perceived as having value to an organization
Asset classification: The practice of labeling assets based on sensitivity and importance to an organization
Asset inventory: A catalog of assets that need to be protected
Asset management: The process of tracking assets and the risks that affect them
Asymmetric encryption: The use of a public and private key pair for encryption and decryption of data
Attack surface: All the potential vulnerabilities that a threat actor could exploit
Attack tree: A diagram that maps threats to assets
Attack vectors: The pathways attackers use to penetrate security defenses
Authentication: The process of verifying who someone is
Automation: The use of technology to reduce human and manual effort to perform common and repetitive tasks
Availability: The idea that data is accessible to those who are authorized to access it
B
Bandwidth: The maximum data transmission capacity over a network, measured by bits per second
Baseline configuration (baseline image): A documented set of specifications within a system that is used as a basis for future builds, releases, and updates
Bash: The default shell in most Linux distributions
Basic auth: The technology used to establish a user’s request to access a server
Basic Input/Output System (BIOS): A microchip that contains loading instructions for the computer and is prevalent in older systems
Biometrics: The unique physical characteristics that can be used to verify a person’s identity
Bit: The smallest unit of data measurement on a computer
Boolean data: Data that can only be one of two values: either True or False
Bootloader: A software program that boots the operating system
Botnet: A collection of computers infected by malware that are under the control of a single threat actor, known as the “bot-herder"
Bracket notation: The indices placed in square brackets
Broken chain of custody: Inconsistencies in the collection and logging of evidence in the chain of custody
Brute force attack: The trial and error process of discovering private information
Bug bounty: Programs that encourage freelance hackers to find and report vulnerabilities
Built-in function: A function that exists within Python and can be called directly
Business continuity: An organization's ability to maintain their everyday productivity by establishing risk disaster recovery plans
Business continuity plan (BCP): A document that outlines the procedures to sustain business operations during and after a significant disruption
Business Email Compromise (BEC): A type of phishing attack where a threat actor impersonates a known source to obtain financial advantage
C
Categorize: The second step of the NIST RMF that is used to develop risk management processes and tasks
CentOS: An open-source distribution that is closely related to Red Hat
Central Processing Unit (CPU): A computer’s main processor, which is used to perform general computing tasks on a computer
Chain of custody: The process of documenting evidence possession and control during an incident lifecycle
Chronicle: A cloud-native tool designed to retain, analyze, and search data
Cipher: An algorithm that encrypts information
Cloud-based firewalls: Software firewalls that are hosted by the cloud service provider
Cloud computing: The practice of using remote servers, applications, and network services that are hosted on the internet instead of on local physical devices
Cloud network: A collection of servers or computers that stores resources and data in remote data centers that can be accessed via the internet
Cloud security: The process of ensuring that assets stored in the cloud are properly configured and access to those assets is limited to authorized users
Command: An instruction telling the computer to do something
Command and control (C2): The techniques used by malicious actors to maintain communications with compromised systems
Command-line interface (CLI): A text-based user interface that uses commands to interact with the computer
Comment: A note programmers make about the intention behind their code
Common Event Format (CEF): A log format that uses key-value pairs to structure data and identify fields and their corresponding values
Common Vulnerabilities and Exposures (CVE®) list: An openly accessible dictionary of known vulnerabilities and exposures
Common Vulnerability Scoring System (CVSS): A measurement system that scores the severity of a vulnerability
Compliance: The process of adhering to internal standards and external regulations
Computer security incident response teams (CSIRT): A specialized group of security professionals that are trained in incident management and response
Computer virus: Malicious code written to interfere with computer operations and cause damage to data and software
Conditional statement: A statement that evaluates code to determine if it meets a specified set of conditions
Confidentiality: The idea that only authorized users can access specific assets or data
Confidential data: Data that often has limits on the number of people who have access to it
Confidentiality, integrity, availability (CIA) triad: A model that helps inform how organizations consider risk when setting up systems and security policies
Configuration file: A file used to configure the settings of an application
Containment: The act of limiting and preventing additional damage caused by an incident
Controlled zone: A subnet that protects the internal network from the uncontrolled zone
Cross-site scripting (XSS): An injection attack that inserts code into a vulnerable website or web application
Crowdsourcing: The practice of gathering information using public input and collaboration
Cryptographic attack: An attack that affects secure forms of communication between a sender and intended recipient
Cryptographic key: A mechanism that decrypts ciphertext
Cryptography: The process of transforming information into a form that unintended readers can’t understand
Cryptojacking: A form of malware that installs software to illegally mine cryptocurrencies
Cybersecurity (or security): The practice of ensuring confidentiality, integrity, and availability of information by protecting networks, devices, people, and data from unauthorized access or criminal exploitation
D
Data: Information that is translated, processed, or stored by a computer
Data at rest: Data not currently being accessed
Database: An organized collection of information or data
Data controller: A person that determines the procedure and purpose for processing data
Data custodian: Anyone or anything that’s responsible for the safe handling, transport, and storage of information
Data exfiltration: Unauthorized transmission of data from a system
Data in transit: Data traveling from one point to another
Data in use: Data being accessed by one or more users
Data owner: The person who decides who can access, edit, use, or destroy their information
Data packet: A basic unit of information that travels from one device to another within a network
Data point: A specific piece of information
Data processor: A person that is responsible for processing data on behalf of the data controller
Data protection officer (DPO): An individual that is responsible for monitoring the compliance of an organization's data protection procedures
Data type: A category for a particular type of data item
Date and time data: Data representing a date and/or time
Debugger: A software tool that helps to locate the source of an error and assess its causes
Debugging: The practice of identifying and fixing errors in code
Defense in depth: A layered approach to vulnerability management that reduces risk
Denial of service (DoS) attack: An attack that targets a network or server and floods it with network traffic
Detect: A NIST core function related to identifying potential security incidents and improving monitoring capabilities to increase the speed and efficiency of detections
Detection: The prompt discovery of security events
Dictionary data: Data that consists of one or more key-value pairs
Digital certificate: A file that verifies the identity of a public key holder
Digital forensics: The practice of collecting and analyzing data to determine what has happened after an attack
Directory: A file that organizes where other files are stored
Disaster recovery plan: A plan that allows an organization’s security team to outline the steps needed to minimize the impact of a security incident
Distributed denial of service (DDoS) attack: A type of denial of service attack that uses multiple devices or servers located in different locations to flood the target network with unwanted traffic
Distributions: The different versions of Linux
Documentation: Any form of recorded content that is used for a specific purpose
DOM-based XSS attack: An instance when malicious script exists in the webpage a browser loads
Domain Name System (DNS): A networking protocol that translates internet domain names into IP addresses
Dropper: A type of malware that comes packed with malicious code which is delivered and installed onto a target system
E
Elevator pitch: A brief summary of your experience, skills, and background
Encapsulation: A process performed by a VPN service that protects your data by wrapping sensitive data in other data packets
Encryption: The process of converting data from a readable format to an encoded format
Endpoint: Any device connected on a network
Endpoint detection and response (EDR): An application that monitors an endpoint for malicious activity
Eradication: The complete removal of the incident elements from all affected systems
Escalation policy: A set of actions that outline who should be notified when an incident alert occurs and how that incident should be handled
Event: An observable occurrence on a network, system, or device
Exception: An error that involves code that cannot be executed even though it is syntactically correct
Exclusive operator: An operator that does not include the value of comparison
Exploit: A way of taking advantage of a vulnerability
Exposure: A mistake that can be exploited by a threat
External threat: Anything outside the organization that has the potential to harm organizational assets
F
False negative: A state where the presence of a threat is not detected
False positive: An alert that incorrectly detects the presence of a threat
Fileless malware: Malware that does not need to be installed by the user because it uses legitimate programs that are already installed to infect a computer
File path: The location of a file or directory
Filesystem Hierarchy Standard (FHS): The component of the Linux OS that organizes data
Filtering: Selecting data that match a certain condition
Final report: Documentation that provides a comprehensive review of an incident
Firewall: A network security device that monitors traffic to or from a network
Float data: Data consisting of a number with a decimal point
Foreign key: A column in a table that is a primary key in another table
Forward proxy server: A server that regulates and restricts a person’s access to the internet
Function: A section of code that can be reused in a program
G
Global variable: A variable that is available through the entire program
Graphical user interface (GUI): A user interface that uses icons on the screen to manage different tasks on the computer
H
Hacker: Any person who uses computers to gain access to computer systems, networks, or data
Hacktivist: A person who uses hacking to achieve a political goal
Hard drive: A hardware component used for long-term memory
Hardware: The physical components of a computer
Hash collision: An instance when different inputs produce the same hash value
Hash function: An algorithm that produces a code that can’t be decrypted
Hash table: A data structure that's used to store and reference hash values
Health Insurance Portability and Accountability Act (HIPAA): A U.S. federal law established to protect patients’ health information
Honeypot: A system or resource created as a decoy vulnerable to attacks with the purpose of attracting potential intruders
Host-based intrusion detection system (HIDS): An application that monitors the activity of the host on which it’s installed
Hub: A network device that broadcasts information to every device on the network
Hypertext Transfer Protocol (HTTP): An application layer protocol that provides a method of communication between clients and website servers
Hypertext Transfer Protocol Secure (HTTPS): A network protocol that provides a secure method of communication between clients and website servers
I
Identify: A NIST core function related to management of cybersecurity risk and its effect on an organization’s people and assets
Identity and access management (IAM): A collection of processes and technologies that helps organizations manage digital identities in their environment
IEEE 802.11 (Wi-Fi): A set of standards that define communication for wireless LANs
Immutable: An object that cannot be changed after it is created and assigned a value
Implement: The fourth step of the NIST RMF that means to implement security and privacy plans for an organization
Improper usage: An incident type that occurs when an employee of an organization violates the organization’s acceptable use policies
Incident: An occurrence that actually or imminently jeopardizes, without lawful authority, the confidentiality, integrity, or availability of information or an information system; or constitutes a violation or imminent threat of violation of law, security policies, security procedures, or acceptable use policies
Incident escalation: The process of identifying a potential security incident, triaging it, and handing it off to a more experienced team member
Incident handler’s journal: A form of documentation used in incident response
Incident response: An organization’s quick attempt to identify an attack, contain the damage, and correct the effects of a security breach
Incident response plan: A document that outlines the procedures to take in each step of incident response
Inclusive operator: An operator that includes the value of comparison
Indentation: Space added at the beginning of a line of code
Index: A number assigned to every element in a sequence that indicates its position
Indicators of attack (IoA): The series of observed events that indicate a real-time incident
Indicators of compromise (IoC): Observable evidence that suggests signs of a potential security incident
Information privacy: The protection of unauthorized access and distribution of data
Information security (InfoSec): The practice of keeping data in all states away from unauthorized users
Injection attack: Malicious code inserted into a vulnerable application
Input validation: Programming that validates inputs from users and other programs
Integer data: Data consisting of a number that does not include a decimal point
Integrated development environment (IDE): A software application for writing code that provides editing assistance and error correction tools
Integrity: The idea that the data is correct, authentic, and reliable
Internal hardware: The components required to run the computer
Internal threat: A current or former employee, external vendor, or trusted partner who poses a security risk
Internet Control Message Protocol (ICMP): An internet protocol used by devices to tell each other about data transmission errors across the network
Internet Control Message Protocol flood (ICMP flood): A type of DoS attack performed by an attacker repeatedly sending ICMP request packets to a network server
Internet Protocol (IP): A set of standards used for routing and addressing data packets as they travel between devices on a network
Internet Protocol (IP) address: A unique string of characters that identifies the location of a device on the internet
Interpreter: A computer program that translates Python code into runnable instructions line by line
Intrusion detection system (IDS): An application that monitors system activity and alerts on possible intrusions
Intrusion prevention system (IPS): An application that monitors system activity for intrusive activity and takes action to stop the activity
IP spoofing: A network attack performed when an attacker changes the source IP of a data packet to impersonate an authorized system and gain access to a network
Iterative statement: Code that repeatedly executes a set of instructions
K
KALI LINUX ™: An open-source distribution of Linux that is widely used in the security industry
Kernel: The component of the Linux OS that manages processes and memory
Key-value pair: A set of data that represents two linked items: a key, and its corresponding value
L
Legacy operating system: An operating system that is outdated but still being used
Lessons learned meeting: A meeting that includes all involved parties after a major incident
Library: A collection of modules that provide code users can access in their programs
Linux: An open-source operating system
List concatenation: The concept of combining two lists into one by placing the elements of the second list directly after the elements of the first list
List data: Data structure that consists of a collection of data in sequential form
Loader: A type of malware that downloads strains of malicious code from an external source and installs them onto a target system
Local Area Network (LAN): A network that spans small areas like an office building, a school, or a home
Local variable: A variable assigned within a function
Log: A record of events that occur within an organization’s systems
Log analysis: The process of examining logs to identify events of interest
Logging: The recording of events occurring on computer systems and networks
Logic error: An error that results when the logic used in code produces unintended results
Log management: The process of collecting, storing, analyzing, and disposing of log data
Loop condition: The part of a loop that determines when the loop terminates
Loop variable: A variable that is used to control the iterations of a loop
M
Malware: Software designed to harm devices or networks
Malware infection: An incident type that occurs when malicious software designed to disrupt a system infiltrates an organization’s computers or network
Media Access Control (MAC) address: A unique alphanumeric identifier that is assigned to each physical device on a network
Method: A function that belongs to a specific data type
Metrics: Key technical attributes such as response time, availability, and failure rate, which are used to assess the performance of a software application
MITRE: A collection of non-profit research and development centers
Modem: A device that connects your router to the internet and brings internet access to the LAN
Module: A Python file that contains additional functions, variables, classes, and any kind of runnable code
Monitor: The seventh step of the NIST RMF that means be aware of how systems are operating
Multi-factor authentication (MFA): A security measure that requires a user to verify their identity in two or more ways to access a system or network
N
nano: A command-line file editor that is available by default in many Linux distributions
National Institute of Standards and Technology (NIST) Cybersecurity Framework (CSF): A voluntary framework that consists of standards, guidelines, and best practices to manage cybersecurity risk
National Institute of Standards and Technology (NIST) Incident Response Lifecycle: A framework for incident response consisting of four phases: Preparation; Detection and Analysis; Containment, Eradication and Recovery, and Post-incident activity
National Institute of Standards and Technology (NIST) Special Publication (S.P.) 800-53: A unified framework for protecting the security of information systems within the U.S. federal government
Network: A group of connected devices
Network-based intrusion detection system (NIDS): An application that collects and monitors network traffic and network data
Network data: The data that’s transmitted between devices on a network
Network Interface Card (NIC): Hardware that connects computers to a network
Network log analysis: The process of examining network logs to identify events of interest
Network protocol analyzer (packet sniffer): A tool designed to capture and analyze data traffic within a network
Network protocols: A set of rules used by two or more devices on a network to describe the order of delivery and the structure of data
Network security: The practice of keeping an organization's network infrastructure secure from unauthorized access
Network segmentation: A security technique that divides the network into segments
Network traffic: The amount of data that moves across a network
Non-repudiation: The concept that the authenticity of information can’t be denied
Notebook: An online interface for writing, storing, and running code
Numeric data: Data consisting of numbers
O
OAuth: An open-standard authorization protocol that shares designated access between applications
Object: A data type that stores data in a comma-separated list of key-value pairs
On-path attack: An attack where a malicious actor places themselves in the middle of an authorized connection and intercepts or alters the data in transit
Open-source intelligence (OSINT): The collection and analysis of information from publicly available sources to generate usable intelligence
Open systems interconnection (OSI) model: A standardized concept that describes the seven layers computers use to communicate and send data over the network
Open Web Application Security Project/Open Worldwide Application Security Project (OWASP): A non-profit organization focused on improving software security
Operating system (OS): The interface between computer hardware and the user
Operator: A symbol or keyword that represents an operation
Options: Input that modifies the behavior of a command
Order of volatility: A sequence outlining the order of data that must be preserved from first to last
OWASP Top 10: A globally recognized standard awareness document that lists the top 10 most critical security risks to web applications
P
Package: A piece of software that can be combined with other packages to form an application
Package manager: A tool that helps users install, manage, and remove packages or applications
Packet capture (P-cap): A file containing data packets intercepted from an interface or network
Packet sniffing: The practice of capturing and inspecting data packets across a network
Parameter (Python): An object that is included in a function definition for use in that function
Parrot: An open-source distribution that is commonly used for security
Parsing: The process of converting data into a more readable format
Passive packet sniffing: A type of attack where a malicious actor connects to a network hub and looks at all traffic on the network
Password attack: An attempt to access password secured devices, systems, networks, or data
Patch update: A software and operating system update that addresses security vulnerabilities within a program or product
Payment Card Industry Data Security Standards (PCI DSS): A set of security standards formed by major organizations in the financial industry
Penetration test (pen test): A simulated attack that helps identify vulnerabilities in systems, networks, websites, applications, and processes
PEP 8 style guide: A resource that provides stylistic guidelines for programmers working in Python
Peripheral devices: Hardware components that are attached and controlled by the computer system
Permissions: The type of access granted for a file or directory
Personally identifiable information (PII): Any information used to infer an individual's identity
Phishing: The use of digital communications to trick people into revealing sensitive data or deploying malicious software
Phishing kit: A collection of software tools needed to launch a phishing campaign
Physical attack: A security incident that affects not only digital but also physical environments where the incident is deployed
Ping of death: A type of DoS attack caused when a hacker pings a system by sending it an oversized ICMP packet that is bigger than 64KB
Playbook: A manual that provides details about any operational action
Policy: A set of rules that reduce risk and protect information
Port: A software-based location that organizes the sending and receiving of data between devices on a network
Port filtering: A firewall function that blocks or allows certain port numbers to limit unwanted communication
Post-incident activity: The process of reviewing an incident to identify areas for improvement during incident handling
Potentially unwanted application (PUA): A type of unwanted software that is bundled in with legitimate programs which might display ads, cause device slowdown, or install other software
Private data: Information that should be kept from the public
Prepare: The first step of the NIST RMF related to activities that are necessary to manage security and privacy risks before a breach occurs
Prepared statement: A coding technique that executes SQL statements before passing them on to a database
Primary key: A column where every row has a unique entry
Principle of least privilege: The concept of granting only the minimal access and authorization required to complete a task or function
Privacy protection: The act of safeguarding personal information from unauthorized use
Procedures: Step-by-step instructions to perform a specific security task
Process of Attack Simulation and Threat Analysis (PASTA): A popular threat modeling framework that’s used across many industries
Programming: A process that can be used to create a specific set of instructions for a computer to execute tasks
Protect: A NIST core function used to protect an organization through the implementation of policies, procedures, training, and tools that help mitigate cybersecurity threats
Protected health information (PHI): Information that relates to the past, present, or future physical or mental health or condition of an individual
Protecting and preserving evidence: The process of properly working with fragile and volatile digital evidence
Proxy server: A server that fulfills the requests of its clients by forwarding them to other servers
Public data: Data that is already accessible to the public and poses a minimal risk to the organization if viewed or shared by others
Public key infrastructure (PKI): An encryption framework that secures the exchange of online information
Python Standard Library: An extensive collection of Python code that often comes packaged with Python
Q
Query: A request for data from a database table or a combination of tables
Quid pro quo: A type of baiting used to trick someone into believing that they’ll be rewarded in return for sharing access, information, or money
R
Rainbow table: A file of pre-generated hash values and their associated plaintext
Random Access Memory (RAM): A hardware component used for short-term memory
Ransomware: A malicious attack where threat actors encrypt an organization’s data and demand payment to restore access
Rapport: A friendly relationship in which the people involved understand each other’s ideas and communicate well with each other
Recover: A NIST core function related to returning affected systems back to normal operation
Recovery: The process of returning affected systems back to normal operations
Red Hat® Enterprise Linux® (also referred to simply as Red Hat in this course): A subscription-based distribution of Linux built for enterprise use
Reflected XSS attack: An instance when malicious script is sent to a server and activated during the server’s response
Regular expression (regex): A sequence of characters that forms a pattern
Regulations: Rules set by a government or other authority to control the way something is done
Relational database: A structured database containing tables that are related to each other
Relative file path: A file path that starts from the user's current directory
Replay attack: A network attack performed when a malicious actor intercepts a data packet in transit and delays it or repeats it at another time
Resiliency: The ability to prepare for, respond to, and recover from disruptions
Respond: A NIST core function related to making sure that the proper procedures are used to contain, neutralize, and analyze security incidents, and implement improvements to the security process
Return statement: A Python statement that executes inside a function and sends information back to the function call
Reverse proxy server: A server that regulates and restricts the internet's access to an internal server
Risk: Anything that can impact the confidentiality, integrity, or availability of an asset
Risk mitigation: The process of having the right procedures and rules in place to quickly reduce the impact of a risk like a breach
Root directory: The highest-level directory in Linux
Rootkit: Malware that provides remote, administrative access to a computer
Root user (or superuser): A user with elevated privileges to modify the system
Router: A network device that connects multiple networks together
S
Salting: An additional safeguard that’s used to strengthen hash functions
Scareware: Malware that employs tactics to frighten users into infecting their device
Search Processing Language (SPL): Splunk’s query language
Secure File Transfer Protocol (SFTP): A secure protocol used to transfer files from one device to another over a network
Secure shell (SSH): A security protocol used to create a shell with a remote system
Security architecture: A type of security design composed of multiple components, such as tools and processes, that are used to protect an organization from risks and external threats
Security audit: A review of an organization's security controls, policies, and procedures against a set of expectations
Security controls: Safeguards designed to reduce specific security risks
Security ethics: Guidelines for making appropriate decisions as a security professional
Security frameworks: Guidelines used for building plans to help mitigate risk and threats to data and privacy
Security governance: Practices that help support, define, and direct security efforts of an organization
Security hardening: The process of strengthening a system to reduce its vulnerabilities and attack surface
Security information and event management (SIEM): An application that collects and analyzes log data to monitor critical activities in an organization
Security mindset: The ability to evaluate risk and constantly seek out and identify the potential or actual breach of a system, application, or data
Security operations center (SOC): An organizational unit dedicated to monitoring networks, systems, and devices for security threats or attacks
Security orchestration, automation, and response (SOAR): A collection of applications, tools, and workflows that use automation to respond to security events
Security posture: An organization’s ability to manage its defense of critical assets and data and react to change
Security zone: A segment of a company’s network that protects the internal network from the internet
Select: The third step of the NIST RMF that means to choose, customize, and capture documentation of the controls that protect an organization
Sensitive data: A type of data that includes personally identifiable information (PII), sensitive personally identifiable information (SPII), or protected health information (PHI)
Sensitive personally identifiable information (SPII): A specific type of PII that falls under stricter handling guidelines
Separation of duties: The principle that users should not be given levels of authorization that would allow them to misuse a system
Session: a sequence of network HTTP requests and responses associated with the same user
Session hijacking: An event when attackers obtain a legitimate user’s session ID
Session ID: A unique token that identifies a user and their device while accessing a system
Set data: Data that consists of an unordered collection of unique values
Shell: The command-line interpreter
Signature: A pattern that is associated with malicious activity
Signature analysis: A detection method used to find events of interest
Simple Network Management Protocol (SNMP): A network protocol used for monitoring and managing devices on a network
Single sign-on (SSO): A technology that combines several different logins into one
Smishing: The use of text messages to trick users to obtain sensitive information or to impersonate a known source
Smurf attack: A network attack performed when an attacker sniffs an authorized user’s IP address and floods it with ICMP packets
Spear phishing: A malicious email attack targeting a specific user or group of users, appearing to originate from a trusted source
Speed: The rate at which a device sends and receives data, measured by bits per second
Splunk Cloud: A cloud-hosted tool used to collect, search, and monitor log data
Splunk Enterprise: A self-hosted tool used to retain, analyze, and search an organization's log data to provide security information and alerts in real-time
Spyware: Malware that’s used to gather and sell information without consent
SQL (Structured Query Language): A programming language used to create, interact with, and request information from a database
SQL injection: An attack that executes unexpected queries on a database
Stakeholder: An individual or group that has an interest in any decision or activity of an organization
Standard error: An error message returned by the OS through the shell
Standard input: Information received by the OS via the command line
Standard output: Information returned by the OS through the shell
Standards: References that inform how to set policies
STAR method: An interview technique used to answer behavioral and situational questions
Stateful: A class of firewall that keeps track of information passing through it and proactively filters out threats
Stateless: A class of firewall that operates based on predefined rules and that does not keep track of information from data packets
Stored XSS attack: An instance when malicious script is injected directly on the server
String concatenation: The process of joining two strings together
String data: Data consisting of an ordered sequence of characters
Style guide: A manual that informs the writing, formatting, and design of documents
Subnetting: The subdivision of a network into logical groups called subnets
Substring: A continuous sequence of characters within a string
Sudo: A command that temporarily grants elevated permissions to specific users
Supply-chain attack: An attack that targets systems, applications, hardware, and/or software to locate a vulnerability where malware can be deployed
Suricata: An open-source intrusion detection system, intrusion prevention system, and network analysis tool
Switch: A device that makes connections between specific devices on a network by sending and receiving data between them
Symmetric encryption: The use of a single secret key to exchange information
Synchronize (SYN) flood attack: A type of DoS attack that simulates a TCP/IP connection and floods a server with SYN packets
Syntax: The rules that determine what is correctly structured in a computing language
Syntax error: An error that involves invalid usage of a programming language
T
TCP/IP model: A framework used to visualize how data is organized and transmitted across a network
tcpdump: A command-line network protocol analyzer
Technical skills: Skills that require knowledge of specific tools, procedures, and policies
Telemetry: The collection and transmission of data for analysis
Threat: Any circumstance or event that can negatively impact assets
Threat actor: Any person or group who presents a security risk
Threat hunting: The proactive search for threats on a network
Threat intelligence: Evidence-based threat information that provides context about existing or emerging threats
Threat modeling: The process of identifying assets, their vulnerabilities, and how each is exposed to threats
Transferable skills: Skills from other areas that can apply to different careers
Transmission Control Protocol (TCP): An internet communication protocol that allows two devices to form a connection and stream data
Triage: The prioritizing of incidents according to their level of importance or urgency
Trojan horse: Malware that looks like a legitimate file or program
True negative: A state where there is no detection of malicious activity
True positive An alert that correctly detects the presence of an attack
Tuple data: Data structure that consists of a collection of data that cannot be changed
Type error: An error that results from using the wrong data type
U
Ubuntu: An open-source, user-friendly distribution that is widely used in security and other industries
Uncontrolled zone: Any network outside your organization's control
Unified Extensible Firmware Interface (UEFI): A microchip that contains loading instructions for the computer and replaces BIOS on more modern systems
USB baiting: An attack in which a threat actor strategically leaves a malware USB stick for an employee to find and install to unknowingly infect a network
User: The person interacting with a computer
User Datagram Protocol (UDP): A connectionless protocol that does not establish a connection between devices before transmissions
User-defined function: A function that programmers design for their specific needs
User interface: A program that allows the user to control the functions of the operating system
User provisioning: The process of creating and maintaining a user's digital identity
V
Variable: A container that stores data
Virtual machine (VM): A virtual version of a physical computer
Virtual Private Network (VPN): A network security service that changes your public IP address and hides your virtual location so that you can keep your data private when you are using a public network like the internet
Virus: Malicious code written to interfere with computer operations and cause damage to data and software
VirusTotal: A service that allows anyone to analyze suspicious files, domains, URLs, and IP addresses for malicious content
Vishing: The exploitation of electronic voice communication to obtain sensitive information or to impersonate a known source
Visual dashboard: A way of displaying various types of data quickly in one place
Vulnerability: A weakness that can be exploited by a threat
Vulnerability assessment: The internal review process of an organization's security systems
Vulnerability management: The process of finding and patching vulnerabilities
Vulnerability scanner: Software that automatically compares existing common vulnerabilities and exposures against the technologies on the network
W
Watering hole attack: A type of attack when a threat actor compromises a website frequently visited by a specific group of users
Web-based exploits: Malicious code or behavior that’s used to take advantage of coding flaws in a web application
Whaling: A category of spear phishing attempts that are aimed at high-ranking executives in an organization
Wide Area Network (WAN): A network that spans a large geographic area like a city, state, or country
Wi-Fi Protected Access (WPA): A wireless security protocol for devices to connect to the internet
Wildcard: A special character that can be substituted with any other character
Wireshark: An open-source network protocol analyzer
World-writable file: A file that can be altered by anyone in the world
Worm: Malware that can duplicate and spread itself across systems on its own
Y
YARA-L: A computer language used to create rules for searching through ingested log data
Z
Zero-day: An exploit that was previously unknown
Dave: Grow your cybersecurity career with mentors
(me who literally hasn't asked for help and when i do its just study, get certs apply)
Welcome to week 1
Introduction to the incident response lifecycle
Incident response teams
Fatima: The importance of communication during incident response
Roles in response
So far, you've been introduced to the National Institute of Standards and Technology (NIST) Incident Response Lifecycle, which is a framework for incident response consisting of four phases:
-
Preparation
-
Detection and Analysis
-
Containment, Eradication, and Recovery
-
Post-incident activity
As a security professional, you'll work on a team to monitor, detect, and respond to incidents. Previously, you learned about a computer security incident response team (CSIRT) and a security operations center (SOC). This reading explains the different functions, roles, and responsibilities that make up CSIRTs and SOCs.
Understanding the composition of incident response teams will help you navigate an organization’s hierarchy, openly collaborate and communicate with others, and work cohesively to respond to incidents. You may even discover specific roles that you’re interested in pursuing as you begin your security career!
Command, control, and communication
A computer security incident response team (CSIRT) is a specialized group of security professionals that are trained in incident management and response. During incident response, teams can encounter a variety of different challenges. For incident response to be effective and efficient, there must be clear command, control, and communication of the situation to achieve the desired goal.
-
Command refers to having the appropriate leadership and direction to oversee the response.
-
Control refers to the ability to manage technical aspects during incident response, like coordinating resources and assigning tasks.
-
Communication refers to the ability to keep stakeholders informed.
Establishing a CSIRT organizational structure with clear and distinctive roles aids in achieving an effective and efficient response.
Roles in CSIRTs
CSIRTs are organization dependent, so they can vary in their structure and operation. Structurally, they can exist as a separate, dedicated team or as a task force that meets when necessary. CSIRTs involve both nonsecurity and security professionals. Nonsecurity professionals are often consulted to offer their expertise on the incident. These professionals can be from external departments, such as human resources, public relations, management, IT, legal, and others. Security professionals involved in a CSIRT typically include three key security related roles:
-
Security analyst
-
Technical lead
-
Incident coordinator
Security analyst
The job of the security analyst is to continuously monitor an environment for any security threats. This includes:
-
Analyzing and triaging alerts
-
Performing root-cause investigations
-
Escalating or resolving alerts
If a critical threat is identified, then analysts escalate it to the appropriate team lead, such as the technical lead.
Technical lead
The job of the technical lead is to manage all of the technical aspects of the incident response process, such as applying software patches or updates. They do this by first determining the root cause of the incident. Then, they create and implement the strategies for containing, eradicating, and recovering from the incident. Technical leads often collaborate with other teams to ensure their incident response priorities align with business priorities, such as reducing disruptions for customers or returning to normal operations.
Incident coordinator
Responding to an incident also requires cross-collaboration with nonsecurity professionals. CSIRTs will often consult with and leverage the expertise of members from external departments. The job of the incident coordinator is to coordinate with the relevant departments during a security incident. By doing so, the lines of communication are open and clear, and all personnel are made aware of the incident status. Incident coordinators can also be found in other teams, like the SOC.
Other roles
Depending on the organization, many other roles can be found in a CSIRT, including a dedicated communications lead, a legal lead, a planning lead, and more.
Note: Teams, roles, responsibilities, and organizational structures can differ for each company. For example, some different job titles for incident coordinator include incident commander and incident manager.
Security operations center
A security operations center (SOC) is an organizational unit dedicated to monitoring networks, systems, and devices for security threats or attacks. Structurally, a SOC (usually pronounced "sock") often exists as its own separate unit or within a CSIRT. You may be familiar with the term blue team, which refers to the security professionals who are responsible for defending against all security threats and attacks at an organization. A SOC is involved in various types of blue team activities, such as network monitoring, analysis, and response to incidents.
SOC organization
A SOC is composed of SOC analysts, SOC leads, and SOC managers. Each role has its own respective responsibilities. SOC analysts are grouped into three different tiers.

Tier 1 SOC analyst
The first tier is composed of the least experienced SOC analysts who are known as level 1s (L1s). They are responsible for:
-
Monitoring, reviewing, and prioritizing alerts based on criticality or severity
-
Creating and closing alerts using ticketing systems
-
Escalating alert tickets to Tier 2 or Tier 3
Tier 2 SOC analyst
The second tier comprises the more experienced SOC analysts, or level 2s (L2s). They are responsible for:
-
Receiving escalated tickets from L1 and conducting deeper investigations
-
Configuring and refining security tools
-
Reporting to the SOC Lead
Tier 3 SOC lead
The third tier of a SOC is composed of the SOC leads, or level 3s (L3s). These highly experienced professionals are responsible for:
-
Managing the operations of their team
-
Exploring methods of detection by performing advanced detection techniques, such as malware and forensics analysis
-
Reporting to the SOC manager
SOC manager
The SOC manager is at the top of the pyramid and is responsible for:
-
Hiring, training, and evaluating the SOC team members
-
Creating performance metrics and managing the performance of the SOC team
-
Developing reports related to incidents, compliance, and auditing
-
Communicating findings to stakeholders such as executive management
Other roles
SOCs can also contain other specialized roles such as:
-
Forensic investigators: Forensic investigators are commonly L2s and L3s who collect, preserve, and analyze digital evidence related to security incidents to determine what happened.
-
Threat hunters: Threat hunters are typically L3s who work to detect, analyze, and defend against new and advanced cybersecurity threats using threat intelligence.
Note: Just like CSIRTs, the organizational structure of a SOC can differ depending on the organization.
Key takeaways
As a security analyst, you will collaborate with your team members and people outside of your immediate team. Recognizing the organizational structure of an incident response team, such as a CSIRT or SOC, will help you understand how incidents move through their lifecycle and the responsibilities of different security roles throughout the process. Knowing the role that you and other professionals have during an incident response event will help you respond to challenging security situations by leveraging different perspectives and thinking of creative solutions.
Resources for more information
Here are some resources if you’d like to learn more about SOC organization or explore other incident response roles:
at Google: Episode 2 of the Hacking Google series of videos
Incident response plans
Incident response tools
The value of documentation
Intrusion detection systems
Overview of detection tools
Previously, you explored intrusion detection system (IDS) and intrusion prevention system (IPS) technologies. In this reading, you’ll compare and contrast these tools and learn about endpoint detection and response (EDR). As a security analyst, you'll likely work with these different tools, so it's important to understand their functions.
Why you need detection tools
Detection tools work similarly to home security systems. Whereas home security systems monitor and protect homes against intrusion, cybersecurity detection tools help organizations protect their networks and systems against unwanted and unauthorized access. For organizations to protect their systems from security threats or attacks, they must be made aware when there is any indication of an intrusion. Detection tools make security professionals aware of the activity happening on a network or a system. The tools do this by continuously monitoring networks and systems for any suspicious activity. Once something unusual or suspicious is detected, the tool triggers an alert that notifies the security professional to investigate and stop the possible intrusion.
Detection tools
As a security analyst, you'll likely encounter IDS, IPS, and EDR detection tools at some point, but it's important to understand the differences between them. Here is a comparison chart for quick reference:
|
Capability |
IDS |
IPS |
EDR |
|---|---|---|---|
|
Detects malicious activity |
✓ |
✓ |
✓ |
|
Prevents intrusions |
N/A |
✓ |
✓ |
|
Logs activity |
✓ |
✓ |
✓ |
|
Generates alerts |
✓ |
✓ |
✓ |
|
Performs behavioral analysis |
N/A |
N/A |
✓ |
Overview of IDS tools
An intrusion detection system (IDS) is an application that monitors system activity and alerts on possible intrusions. An IDS provides continuous monitoring of network events to help protect against security threats or attacks. The goal of an IDS is to detect potential malicious activity and generate an alert once such activity is detected. An IDS does not stop or prevent the activity. Instead, security professionals will investigate the alert and act to stop it, if necessary.
For example, an IDS can send out an alert when it identifies a suspicious user login, such as an unknown IP address logging into an application or a device at an unusual time. But, an IDS will not stop or prevent any further actions, like blocking the suspicious user login.
Examples of IDS tools include Zeek, Suricata, Snort®, and Sagan.
Detection categories
As a security analyst, you will investigate alerts that an IDS generates. There are four types of detection categories you should be familiar with:
-
A true positive is an alert that correctly detects the presence of an attack.
-
A true negative is a state where there is no detection of malicious activity. This is when no malicious activity exists and no alert is triggered.
-
A false positive is an alert that incorrectly detects the presence of a threat. This is when an IDS identifies an activity as malicious, but it isn't. False positives are an inconvenience for security teams because they spend time and resources investigating an illegitimate alert.
-
A false negative is a state where the presence of a threat is not detected. This is when malicious activity happens but an IDS fails to detect it. False negatives are dangerous because security teams are left unaware of legitimate attacks that they can be vulnerable to.
Overview of IPS tools
An intrusion prevention system (IPS) is an application that monitors system activity for intrusive activity and takes action to stop the activity. An IPS works similarly to an IDS. But, IPS monitors system activity to detect and alert on intrusions, and it also takes action to prevent the activity and minimize its effects. For example, an IPS can send an alert and modify an access control list on a router to block specific traffic on a server.
Note: Many IDS tools can also operate as an IPS. Tools like Suricata, Snort, and Sagan have both IDS and IPS capabilities.
Overview of EDR tools
Endpoint detection and response (EDR) is an application that monitors an endpoint for malicious activity. EDR tools are installed on endpoints. Remember that an endpoint is any device connected on a network. Examples include end-user devices, like computers, phones, tablets, and more.
EDR tools monitor, record, and analyze endpoint system activity to identify, alert, and respond to suspicious activity. Unlike IDS or IPS tools, EDRs collect endpoint activity data and perform behavioral analysis to identify threat patterns happening on an endpoint. Behavioral analysis uses the power of machine learning and artificial intelligence to analyze system behavior to identify malicious or unusual activity. EDR tools also use automation to stop attacks without the manual intervention of security professionals. For example, if an EDR detects an unusual process starting up on a user’s workstation that normally is not used, it can automatically block the process from running.
Tools like Open EDR®, Bitdefender™ Endpoint Detection and Response, and FortiEDR™ are examples of EDR tools.
Note: Security information and event management (SIEM) tools also have detection capabilities, which you'll explore later.
Key takeaways
Organizations deploy detection tools to gain awareness into the activity happening in their environments. IDS, IPS, and EDR are different types of detection tools. The value of detection tools is in their ability to detect, log, alert, and stop potential malicious activity.
Alert and event management with SIEM and SOAR tools
Wrap-up; Terms and definitions from Course 6, Week 1
Glossary terms from week 1
Terms and definitions from Course 6, Week 1
Computer security incident response teams (CSIRT): A specialized group of security professionals that are trained in incident management and response
Documentation: Any form of recorded content that is used for a specific purpose
Endpoint detection and response (EDR): An application that monitors an endpoint for malicious activity
Event: An observable occurrence on a network, system, or device
False negative: A state where the presence of a threat is not detected
False positive: An alert that incorrectly detects the presence of a threat
Incident: An occurrence that actually or imminently jeopardizes, without lawful authority, the confidentiality, integrity, or availability of information or an information system; or constitutes a violation or imminent threat of violation of law, security policies, security procedures, or acceptable use policies
Incident handler’s journal: A form of documentation used in incident response
Incident response plan: A document that outlines the procedures to take in each step of incident response
Intrusion detection system (IDS): An application that monitors system activity and alerts on possible intrusions
Intrusion prevention system (IPS): An application that monitors system activity for intrusive activity and takes action to stop the activity
National Institute of Standards and Technology (NIST) Incident Response Lifecycle: A framework for incident response consisting of four phases: Preparation; Detection and Analysis; Containment, Eradication, and Recovery; and Post-incident activity
Playbook: A manual that provides details about any operational action
Security information and event management (SIEM): An application that collects and analyzes log data to monitor critical activities in an organization
Security operations center (SOC): An organizational unit dedicated to monitoring networks, systems, and devices for security threats or attacks
Security orchestration, automation, and response (SOAR): A collection of applications, tools, and workflows that uses automation to respond to security events
True negative: A state where there is no detection of malicious activity
True positive An alert that correctly detects the presence of an attack
Welcome to week 2
Casey: Apply soft skills in cybersecurity
The importance of network traffic flows
Maintain awareness with network monitoring
Network communication can be noisy! Events like sending an email, streaming a video, or visiting a website all produce network communications in the form of network traffic and network data. As a reminder, network traffic is the amount of data that moves across a network. It can also include the type of data that is transferred, such as HTTP. Network data is the data that's transmitted between devices on a network.
Network monitoring is essential in maintaining situational awareness of any activity on a network. By collecting and analyzing network traffic, organizations can detect suspicious network activity. But before networks can be monitored, you must know exactly what to monitor. In this reading, you'll learn more about the importance of network monitoring, ways to monitor your network, and network monitoring tools.
Know your network
As you’ve learned, networks connect devices, and devices then communicate and exchange data using network protocols. Network communications provide information about connections such as source and destination IP addresses, amount of data transferred, date and time, and more. This information can be valuable for security professionals when developing a baseline of normal or expected behavior.

A baseline is a reference point that’s used for comparison. You've probably encountered or used baselines at some point. For example, a grocery amount for a personal budget is an example of a baseline that can be used to help identify any patterns or changes in spending habits. In security, baselines help establish a standard of expected or normal behavior for systems, devices, and networks. Essentially, by knowing the baseline of normal network behavior, you'll be better able to identify abnormal network behavior.
Monitor your network
Once you’ve determined a baseline, you can monitor a network to identify any deviations from that baseline. Monitoring involves examining network components to detect unusual activities, such as large and unusual data transfers. Here are examples of network components that can be monitored to detect malicious activity:
Flow analysis
Flow refers to the movement of network communications and includes information related to packets, protocols, and ports. Packets can travel to ports, which receive and transmit communications. Ports are often, but not always, associated with network protocols. For example, port 443 is commonly used by HTTPS which is a protocol that provides website traffic encryption.
However, malicious actors can use protocols and ports that are not commonly associated to maintain communications between the compromised system and their own machine. These communications are what’s known as command and control (C2), which are the techniques used by malicious actors to maintain communications with compromised systems.
For example, malicious actors can use HTTPS protocol over port 8088 as opposed to its commonly associated port 443 to communicate with compromised systems. Organizations must know which ports should be open and approved for connections, and watch out for any mismatches between ports and their associated protocols.
Packet payload information
Network packets contain components related to the transmission of the packet. This includes details like source and destination IP address, and the packet payload information, which is the actual data that’s transmitted. Often, this data is encrypted and requires decryption for it to be readable. Organizations can monitor the payload information of packets to uncover unusual activity, such as sensitive data transmitting outside of the network, which could indicate a possible data exfiltration attack.
Temporal patterns
Network packets contain information relating to time. This information is useful in understanding time patterns. For example, a company operating in North America experiences bulk traffic flows between 9 a.m. to 5 p.m., which is the baseline of normal network activity. If large volumes of traffic are suddenly outside of the normal hours of network activity, then this is considered off baseline and should be investigated.
Through network monitoring, organizations can promptly detect network intrusions and work to prevent them from happening by securing network components.
Protect your network
In this program, you’ve learned about security operations centers (SOC) and their role in monitoring systems against security threats and attacks. Organizations may deploy a network operations center (NOC), which is an organizational unit that monitors the performance of a network and responds to any network disruption, such as a network outage. While a SOC is focused on maintaining the security of an organization through detection and response, a NOC is responsible for maintaining network performance, availability, and uptime.

Security analysts monitor networks to identify any signs of potential security incidents known as indicators of compromise (IoC) and protect networks from threats or attacks. To do this, they must understand the environment that network communications travel through so that they can identify deviations in network traffic.
Network monitoring tools
Network monitoring can be automated or performed manually. Some common network monitoring tools can include:
-
Intrusion detection systems (IDS) monitor system activity and alert on possible intrusions. An IDS will detect and alert on the deviations you’ve configured it to detect. Most commonly, IDS tools will monitor the content of packet payload to detect patterns associated with threats such as malware or phishing attempts.
-
Network protocol analyzers, also known as packet sniffers, are tools designed to capture and analyze data traffic within a network. They can be used to analyze network communications manually in detail. Examples include tools such as tcpdump and Wireshark, which can be used by security professionals to record network communications through packet captures. Packet captures can then be investigated to identify potentially malicious activity.
Key takeaways
Monitoring and protecting networks from intrusions and attacks are key responsibilities of security professionals. You can’t protect what you don’t know. As a security analyst, you’ll need to know the components of a network and the communications that happen on it, so you can better protect it. Baselines provide a way to understand network traffic by uncovering common patterns which help in identifying any deviations from the expected traffic patterns. Tools like intrusion detection systems and network protocol analyzers support efforts in monitoring network activities.
Resources
-
If you would like to learn more about network components organizations can monitor, check out network traffic - MITRE ATT&CK®
-
-
Attackers can leverage different techniques to exfiltrate data, should you like to learn more, check out data exfiltration techniques - MITRE ATT&CK®
Data exfiltration attacks
Packets and packet captures
Learn more about packet captures
The role of security analysts involves monitoring and analyzing network traffic flows. One way to do this is by generating packet captures and then analyzing the captured traffic to identify unusual activity on a network.
Previously, you explored the fundamentals of networks. Throughout this section, you’ll refer to your foundation in networking to better understand network traffic flows. In this reading, you'll learn about the three main aspects of network analysis: packets, network protocol analyzers, and packet captures.
Packets
Previously in the program, you learned that a data packet is a basic unit of information that travels from one device to another within a network. Detecting network intrusions begins at the packet level. That's because packets form the basis of information exchange over a network. Each time you perform an activity on the internet—like visiting a website—packets are sent and received between your computer and the website’s server. These packets are what help transmit information through a network. For example, when uploading an image to a website, the data gets broken up into multiple packets, which then get routed to the intended destination and reassembled upon delivery.
In cybersecurity, packets provide valuable information that helps add context to events during investigations. Understanding the transfer of information through packets will not only help you develop insight on network activity, it will also help you identify abnormalities and better defend networks from attacks.
Packets contain three components: the header, the payload, and the footer. Here’s a description of each of these components.
Header
Packets begin with the most essential component: the header. Packets can have several headers depending on the protocols used such as an Ethernet header, an IP header, a TCP header, and more. Headers provide information that’s used to route packets to their destination. This includes information about the source and destination IP addresses, packet length, protocol, packet identification numbers, and more.
Here is an IPv4 header with the information it provides:

Payload
The payload component directly follows the header and contains the actual data being delivered. Think back to the example of uploading an image to a website; the payload of this packet would be the image itself.
Footer
Note: Most protocols, such as the Internet Protocol (IP), do not use footers.
Network protocol analyzers
Network protocol analyzers (packet sniffers) are tools designed to capture and analyze data traffic within a network. Examples of network protocol analyzers include tcpdump, Wireshark, and TShark.
Beyond their use in security as an investigative tool used to monitor networks and identify suspicious activity, network protocol analyzers can be used to collect network statistics, such as bandwidth or speed, and troubleshoot network performance issues, like slowdowns.
Network protocol analyzers can also be used for malicious purposes. For example, malicious actors can use network protocol analyzers to capture packets containing sensitive data, such as account login information.
Here’s a network diagram illustrating how packets get transmitted from a sender to the receiver. A network protocol analyzer is placed in the middle of the communications to capture the data packets that travel over the wire.

How network protocol analyzers work
Network protocol analyzers use both software and hardware capabilities to capture network traffic and display it for security analysts to examine and analyze. Here’s how:
-
First, packets must be collected from the network via the Network Interface Card (NIC), which is hardware that connects computers to a network, like a router. NICs receive and transmit network traffic, but by default they only listen to network traffic that’s addressed to them. To capture all network traffic that is sent over the network, a NIC must be switched to a mode that has access to all visible network data packets. In wireless interfaces this is often referred to as monitoring mode, and in other systems it may be called promiscuous mode. This mode enables the NIC to have access to all visible network data packets, but it won’t help analysts access all packets across a network. A network protocol analyzer must be positioned in an appropriate network segment to access all traffic between different hosts.
-
The network protocol analyzer collects the network traffic in raw binary format. Binary format consists of 0s and 1s and is not as easy for humans to interpret. The network protocol analyzer takes the binary and converts it so that it’s displayed in a human-readable format, so analysts can easily read and understand the information.
Capturing packets
Packet sniffing is the practice of capturing and inspecting data packets across a network. A packet capture (p-cap) is a file containing data packets intercepted from an interface or network. Packet captures can be viewed and further analyzed using network protocol analyzers. For example, you can filter packet captures to only display information that's most relevant to your investigation, such as packets sent from a specific IP address.
Note: Using network protocol analyzers to intercept and examine private network communications without permission is considered illegal in many places.
P-cap files can come in many formats depending on the packet capture library that’s used. Each format has different uses and network tools may use or support specific packet capture file formats by default. You should be familiar with the following libraries and formats:
-
Libpcap is a packet capture library designed to be used by Unix-like systems, like Linux and MacOS®. Tools like tcpdump use Libpcap as the default packet capture file format.
-
WinPcap is an open-source packet capture library designed for devices running Windows operating systems. It’s considered an older file format and isn’t predominantly used.
-
Npcap is a library designed by the port scanning tool Nmap that is commonly used in Windows operating systems.
-
PCAPng is a modern file format that can simultaneously capture packets and store data. Its ability to do both explains the “ng,” which stands for “next generation.”
Pro tip: Analyzing your home network can be a good way to practice using these tools.
Key takeaways
Network protocol analyzers are helpful investigative tools that provide you with insight into the activity happening on a network. As an analyst, you'll use network protocol analyzer tools to view and analyze packet capture files to better understand network communications and defend against intrusions.
Resources for more information
This Infosec article describes the risks of packet crafting
, a technique used to test a network’s structure.
Interpret network communications with packets
Reexamine the fields of a packet header
Investigate packet details
So far, you've learned about how network protocol analyzers (packet sniffers) intercept network communications. You've also learned how you can analyze packet captures (p-caps) to gain insight into the activity happening on a network. As a security analyst, you'll use your packet analysis skills to inspect network packets and identify suspicious activity during investigations.
In this reading, you'll re-examine IPv4 and IPv6 headers. Then, you'll explore how you can use Wireshark to investigate the details of packet capture files.
Internet Protocol (IP)
Packets form the foundation of data exchange over a network, which means that detection begins at the packet level. The Internet Protocol (IP) includes a set of standards used for routing and addressing data packets as they travel between devices on a network. IP operates as the foundation for all communications over the internet.
IP ensures that packets reach their destinations. There are two versions of IP that you will find in use today: IPv4 and IPv6. Both versions use different headers to structure packet information.
IPv4
IPv4 is the most commonly used version of IP. There are thirteen fields in the header:
-
Version: This field indicates the IP version. For an IPv4 header, IPv4 is used.
-
Internet Header Length (IHL): This field specifies the length of the IPv4 header including any Options.
-
Type of Service (ToS): This field provides information about packet priority for delivery.
-
Total Length: This field specifies the total length of the entire IP packet including the header and the data.
-
Identification: Packets that are too large to send are fragmented into smaller pieces. This field specifies a unique identifier for fragments of an original IP packet so that they can be reassembled once they reach their destination.
-
Flags: This field provides information about packet fragmentation including whether the original packet has been fragmented and if there are more fragments in transit.
-
Fragment Offset: This field is used to identify the correct sequence of fragments.
-
Time to Live (TTL): This field limits how long a packet can be circulated in a network, preventing packets from being forwarded by routers indefinitely.
-
Protocol: This field specifies the protocol used for the data portion of the packet.
-
Header Checksum: This field specifies a checksum value which is used for error-checking the header.
-
Source Address: This field specifies the source address of the sender.
-
Destination Address: This field specifies the destination address of the receiver.
-
Options: This field is optional and can be used to apply security options to a packet.

IPv6
IPv6 adoption has been increasing because of its large address space. There are eight fields in the header:
-
Version: This field indicates the IP version. For an IPv6 header, IPv6 is used.
-
Traffic Class: This field is similar to the IPv4 Type of Service field. The Traffic Class field provides information about the packet's priority or class to help with packet delivery.
-
Flow Label: This field identifies the packets of a flow. A flow is the sequence of packets sent from a specific source.
-
Payload Length: This field specifies the length of the data portion of the packet.
-
Next Header: This field indicates the type of header that follows the IPv6 header such as TCP.
-
Hop Limit: This field is similar to the IPv4 Time to Live field. The Hop Limit limits how long a packet can travel in a network before being discarded.
-
Source Address: This field specifies the source address of the sender.
-
Destination Address: This field specifies the destination address of the receiver.

Header fields contain valuable information for investigations and tools like Wireshark help to display these fields in a human-readable format.
Wireshark
Wireshark is an open-source network protocol analyzer. It uses a graphical user interface (GUI), which makes it easier to visualize network communications for packet analysis purposes. Wireshark has many features to explore that are beyond the scope of this course. You'll focus on how to use basic filtering to isolate network packets so that you can find what you need.

Display filters
Wireshark's display filters let you apply filters to packet capture files. This is helpful when you are inspecting packet captures with large volumes of information. Display filters will help you find specific information that's most relevant to your investigation. You can filter packets based on information such as protocols, IP addresses, ports, and virtually any other property found in a packet. Here, you'll focus on display filtering syntax and filtering for protocols, IP addresses, and ports.
Comparison operators
You can use different comparison operators to locate specific header fields and values. Comparison operators can be expressed using either abbreviations or symbols. For example, this filter using the == equal symbol in this filter ip.src == 8.8.8.8 is identical to using the eq abbreviation in this filter ip.src eq 8.8.8.8.
This table summarizes the different types of comparison operators you can use for display filtering.
|
Operator type |
Symbol |
Abbreviation |
|---|---|---|
|
Equal |
== |
eq |
|
Not equal |
!= |
ne |
|
Greater than |
> |
gt |
|
Less than |
< |
lt |
|
Greater than or equal to |
>= |
ge |
|
Less than or equal to |
<= |
le |
Pro tip: You can combine comparison operators with Boolean logical operators like and and or to create complex display filters. Parentheses can also be used to group expressions and to prioritize search terms.
Contains operator
The contains operator is used to filter packets that contain an exact match of a string of text. Here is an example of a filter that displays all HTTP streams that match the keyword "moved".

Matches operator
The matches operator is used to filter packets based on the regular expression (regex) that's specified. Regular expression is a sequence of characters that forms a pattern. You'll explore more about regular expressions later in this program.
Filter toolbar
You can apply filters to a packet capture using Wireshark's filter toolbar. In this example, dns is the applied filter, which means Wireshark will only display packets containing the DNS protocol.

Pro tip: Wireshark uses different colors to represent protocols. You can customize colors and create your own filters.
Filter for protocols
Protocol filtering is one of the simplest ways you can use display filters. You can simply enter the name of the protocol to filter. For example, to filter for DNS packets simply type dns in the filter toolbar. Here is a list of some protocols you can filter for:
-
dns
-
http
-
ftp
-
ssh
-
arp
-
telnet
-
icmp
Filter for an IP address
You can use display filters to locate packets with a specific IP address.
For example, if you would like to filter packets that contain a specific IP address use ip.addr, followed by a space, the equal == comparison operator, and the IP address. Here is an example of a display filter that filters for the IP address 172.21.224.2:
ip.addr == 172.21.224.2
To filter for packets originating from a specific source IP address, you can use the ip.src filter. Here is an example that looks for the 10.10.10.10 source IP address:
ip.src == 10.10.10.10
To filter for packets delivered to a specific destination IP address, you can use the ip.dst filter. Here is an example that searches for the 4.4.4.4 destination IP address:
ip.dst == 4.4.4.4
Filter for a MAC address
You can also filter packets according to the Media Access Control (MAC) address. As a refresher, a MAC address is a unique alphanumeric identifier that is assigned to each physical device on a network.
Here's an example:
eth.addr == 00:70:f4:23:18:c4
Filter for ports
Port filtering is used to filter packets based on port numbers. This is helpful when you want to isolate specific types of traffic. DNS traffic uses TCP or UDP port 53 so this will list traffic related to DNS queries and responses only.
For example, if you would like to filter for a UDP port:
udp.port == 53
Likewise, you can filter for TCP ports as well:
tcp.port == 25
Follow streams
Wireshark provides a feature that lets you filter for packets specific to a protocol and view streams. A stream or conversation is the exchange of data between devices using a protocol. Wireshark reassembles the data that was transferred in the stream in a way that's simple to read.

Following a protocol stream is useful when trying to understand the details of a conversation. For example, you can examine the details of an HTTP conversation to view the content of the exchanged request and response messages.
Key takeaways
In this reading, you explored basic display filters with Wireshark. Packet analysis is an essential skill that you will continue to develop over time in your cybersecurity journey. Put your skills to practice in the upcoming activity and explore investigating the details of a packet capture file using Wireshark!
Resources
-
To learn more about Wireshark's full features and capabilities, explore the Wireshark official user guide
Extra
- the next page in Coursera's course is on using wireshark. so if you are doing this in advanced, go install it and try to use it :D
Packet captures with tcpdump
example tcp dump activity
Use ifconfig to identify the interfaces that are available:
sudo ifconfigexample output
analyst@b4aade4b3e15:~$ sudo ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1460
inet 172.18.0.2 netmask 255.255.0.0 broadcast 172.18.255.255
ether 02:42:ac:12:00:02 txqueuelen 0 (Ethernet)
RX packets 760 bytes 13683706 (13.0 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 523 bytes 44695 (43.6 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 53 bytes 8173 (7.9 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 53 bytes 8173 (7.9 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0The Ethernet network interface is identified by the entry with the eth prefix.
So, in this lab, you'll use eth0 as the interface that you will capture network packet data from in the following tasks.
Use tcpdump to identify the interface options available for packet capture:
sudo tcpdump -Dexample output
analyst@b4aade4b3e15:~$ sudo tcpdump -D
1.eth0 [Up, Running]
2.any (Pseudo-device that captures on all interfaces) [Up, Running]
3.lo [Up, Running, Loopback]
4.nflog (Linux netfilter log (NFLOG) interface)
5.nfqueue (Linux netfilter queue (NFQUEUE) interface)This command will also allow you to identify which network interfaces are available. This may be useful on systems that do not include the ifconfig command.
Inspect the network traffic of a network interface with tcpdump
In this task, you must use tcpdump to filter live network packet traffic on an interface.
- Filter live network packet data from the
eth0interface withtcpdump:
sudo tcpdump -i eth0 -v -c5-
This command will run
tcpdumpwith the following options:-i eth0: Capture data specifically from theeth0interface.-v: Display detailed packet data.-c5: Capture 5 packets of data.
Now, let's take a detailed look at the packet information that this command has returned.
Some of your packet traffic data will be similar to the following example output:
analyst@b4aade4b3e15:~$ sudo tcpdump -i eth0 -v -c5
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
13:34:41.849715 IP (tos 0x0, ttl 64, id 5124, offset 0, flags [DF], proto TCP (6), length 113)
b4aade4b3e15.5000 > nginx-us-central1-b.c.qwiklabs-terminal-vms-prod-00.internal.35886: Flags [P.], cksum 0x588b (incorrect -> 0x2db4), seq 824003473:824003534, ack 494355080, win 501, options [nop,nop,TS val 3565226228 ecr 381006698], length 61
13:34:41.849984 IP (tos 0x0, ttl 63, id 46029, offset 0, flags [DF], proto TCP (6), length 52)
nginx-us-central1-b.c.qwiklabs-terminal-vms-prod-00.internal.35886 > b4aade4b3e15.5000: Flags [.], cksum 0xf838 (correct), ack 61, win 507, options [nop,nop,TS val 381006741 ecr 3565226228], length 0
13:34:41.850797 IP (tos 0x0, ttl 64, id 56996, offset 0, flags [DF], proto UDP (17), length 69)
b4aade4b3e15.32961 > metadata.google.internal.domain: 15232+ PTR? 2.0.17.172.in-addr.arpa. (41)
13:34:41.853851 IP (tos 0x0, ttl 63, id 0, offset 0, flags [none], proto UDP (17), length 143)
metadata.google.internal.domain > b4aade4b3e15.32961: 15232 1/0/0 2.0.17.172.in-addr.arpa. PTR nginx-us-central1-b.c.qwiklabs-terminal-vms-prod-00.internal. (115)
13:34:41.854922 IP (tos 0x0, ttl 64, id 9599, offset 0, flags [DF], proto UDP (17), length 74)
b4aade4b3e15.56670 > metadata.google.internal.domain: 49479+ PTR? 254.169.254.169.in-addr.arpa. (46)
5 packets captured
6 packets received by filter
0 packets dropped by kerneThe specific packet data in your lab may be in a different order and may even be for entirely different types of network traffic. The specific details, such as system names, ports, and checksums, will definitely be different. You can run this command again to get different snapshots to outline how data changes between packets.
Exploring network packet details
In this example, you’ll identify some of the properties that tcpdump outputs for the packet capture data you’ve just seen.
- In the example data at the start of the packet output,
tcpdumpreported that it was listening on theeth0interface, and it provided information on the link type and the capture size in bytes:tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes - On the next line, the first field is the packet's timestamp, followed by the protocol type, IP:
22:24:18.910372 IP - The verbose option,
-v, has provided more details about the IP packet fields, such as TOS, TTL, offset, flags, internal protocol type (in this case, TCP (6)), and the length of the outer IP packet in bytes:
The specific details about these fields are beyond the scope of this lab. But you should know that these are properties that relate to the IP network packet.(tos 0x0, ttl 64, id 5802, offset 0, flags [DF], proto TCP (6), length 134) - In the next section, the data shows the systems that are communicating with each other:
7acb26dc1f44.5000 > nginx-us-east1-c.c.qwiklabs-terminal-vms-prod-00.internal.59788:By default,
tcpdumpwill convert IP addresses into names, as in the screenshot. The name of your Linux virtual machine, also included in the command prompt, appears here as the source for one packet and the destination for the second packet. In your live data, the name will be a different set of letters and numbers.The direction of the arrow (>) indicates the direction of the traffic flow in this packet. Each system name includes a suffix with the port number (.5000 in the screenshot), which is used by the source and the destination systems for this packet.
- The remaining data filters the header data for the inner TCP packet:
Flags [P.], cksum 0x5851 (incorrect > 0x30d3), seq 1080713945:1080714027, ack 62760789, win 501, options [nop,nop,TS val 1017464119 ecr 3001513453], length 82The flags field identifies TCP flags. In this case, the P represents the push flag and the period indicates it's an ACK flag. This means the packet is pushing out data.
The next field is the TCP checksum value, which is used for detecting errors in the data.
This section also includes the sequence and acknowledgment numbers, the window size, and the length of the inner TCP packet in bytes.
Capture network traffic with tcpdump
In this task, you will use tcpdump to save the captured network data to a packet capture file.
In the previous command, you used tcpdump to stream all network traffic. Here, you will use a filter and other tcpdump configuration options to save a small sample that contains only web (TCP port 80) network packet data.
- Capture packet data into a file called
capture.pcap:sudo tcpdump -i eth0 -nn -c9 port 80 -w capture.pcap &analyst@b4aade4b3e15:~$ sudo tcpdump -i eth0 -nn -c9 port 80 -w capture.pcap & [1] 12811 tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytesYou may need to press the ENTER key to get your command prompt back after running this command.
This command will run
tcpdumpin the background with the following options:-i eth0: Capture data from theeth0interface.-nn: Do not attempt to resolve IP addresses or ports to names.This is best practice from a security perspective, as the lookup data may not be valid. It also prevents malicious actors from being alerted to an investigation.-c9: Capture 9 packets of data and then exit.port 80: Filter only port 80 traffic. This is the default HTTP port.-w capture.pcap: Save the captured data to the named file.&: This is an instruction to the Bash shell to run the command in the background.
This command runs in the background, but some output text will appear in your terminal. The text will not affect the commands when you follow the steps for the rest of the lab.
- Use
curlto generate some HTTP (port 80) traffic:
When thecurl opensource.google.comcurlcommand is used like this to open a website, it generates some HTTP (TCP port 80) traffic that can be captured.analyst@b4aade4b3e15:~$ curl opensource.google.com <HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8"> <TITLE>301 Moved</TITLE></HEAD><BODY> <H1>301 Moved</H1> The document has moved <A HREF="https://opensource.google/">here</A>. </BODY></HTML> analyst@b4aade4b3e15:~$ 9 packets captured 10 packets received by filter 0 packets dropped by kernel [1]+ Done sudo tcpdump -i eth0 -nn -c9 port 80 -w capture.pcap -
Verify that packet data has been captured:
ls -l capture.pcapNote: The "Done" in the output indicates that the packet was captured.
analyst@b4aade4b3e15:~$ ls -l capture.pcap -rw-r--r-- 1 root root 1445 Sep 13 13:51 capture.pcap
Filter the captured packet data
In this task, use tcpdump to filter data from the packet capture file you saved previously.
- Use the
tcpdumpcommand to filter the packet header data from thecapture.pcapcapture file:sudo tcpdump -nn -r capture.pcap -vexample output:
analyst@b4aade4b3e15:~$ sudo tcpdump -nn -r capture.pcap -v reading from file capture.pcap, link-type EN10MB (Ethernet) 13:51:00.530684 IP (tos 0x0, ttl 64, id 58151, offset 0, flags [DF], proto TCP (6), length 60) 172.18.0.2.48328 > 64.233.182.139.80: Flags [S], cksum 0xa3b7 (incorrect -> 0xfeb3), seq 3977332362, win 65320, options [mss 1420,sackOK,TS val 109490055 ecr 0,nop,wscale 7], length 0 13:51:00.531500 IP (tos 0x60, ttl 126, id 0, offset 0, flags [DF], proto TCP (6), length 60) 64.233.182.139.80 > 172.18.0.2.48328: Flags [S.], cksum 0xddb4 (correct), seq 1521600211, ack 3977332363, win 65535, options [mss 1420,sackOK,TS val 4261937288 ecr 109490055,nop,wscale 8], length 0 13:51:00.531518 IP (tos 0x0, ttl 64, id 58152, offset 0, flags [DF], proto TCP (6), length 52) 172.18.0.2.48328 > 64.233.182.139.80: Flags [.], cksum 0xa3af (incorrect -> 0x0a5a), ack 1, win 511, options [nop,nop,TS val 109490056 ecr 4261937288], length 0 13:51:00.531593 IP (tos 0x0, ttl 64, id 58153, offset 0, flags [DF], proto TCP (6), length 137) 172.18.0.2.48328 > 64.233.182.139.80: Flags [P.], cksum 0xa404 (incorrect -> 0x790d), seq 1:86, ack 1, win 511, options [nop,nop,TS val 109490056 ecr 4261937288], length 85: HTTP, length: 85 GET / HTTP/1.1 Host: opensource.google.com User-Agent: curl/7.64.0 Accept: */* 13:51:00.531808 IP (tos 0x60, ttl 126, id 0, offset 0, flags [DF], proto TCP (6), length 52) 64.233.182.139.80 > 172.18.0.2.48328: Flags [.], cksum 0x0b03 (correct), ack 86, win 256, options [nop,nop,TS val 4261937289 ecr 109490056], length 0 13:51:00.533901 IP (tos 0x80, ttl 126, id 0, offset 0, flags [DF], proto TCP (6), length 634) 64.233.182.139.80 > 172.18.0.2.48328: Flags [P.], cksum 0xf3cd (correct), seq 1:583, ack 86, win 256, options [nop,nop,TS val 4261937291 ecr 109490056], length 582: HTTP, length: 582 HTTP/1.1 301 Moved Permanently Location: https://opensource.google/ Cross-Origin-Resource-Policy: cross-origin Content-Type: text/html; charset=UTF-8 X-Content-Type-Options: nosniff Date: Wed, 13 Sep 2023 13:51:00 GMT Expires: Wed, 13 Sep 2023 14:21:00 GMT Cache-Control: public, max-age=1800 Server: sffe Content-Length: 223 X-XSS-Protection: 0 <HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8"> <TITLE>301 Moved</TITLE></HEAD><BODY> <H1>301 Moved</H1> The document has moved <A HREF="https://opensource.google/">here</A>. </BODY></HTML> 13:51:00.533907 IP (tos 0x0, ttl 64, id 58154, offset 0, flags [DF], proto TCP (6), length 52) 172.18.0.2.48328 > 64.233.182.139.80: Flags [.], cksum 0xa3af (incorrect -> 0x07be), ack 583, win 507, options [nop,nop,TS val 109490058 ecr 4261937291], length 0 13:51:00.535313 IP (tos 0x0, ttl 64, id 58155, offset 0, flags [DF], proto TCP (6), length 52) 172.18.0.2.48328 > 64.233.182.139.80: Flags [F.], cksum 0xa3af (incorrect -> 0x07bb), seq 86, ack 583, win 507, options [nop,nop,TS val 109490060 ecr 4261937291], length 0 13:51:00.535704 IP (tos 0x80, ttl 126, id 0, offset 0, flags [DF], proto TCP (6), length 52) 64.233.182.139.80 > 172.18.0.2.48328: Flags [F.], cksum 0x08b4 (correct), seq 583, ack 87, win 256, options [nop,nop,TS val 4261937292 ecr 109490060], length 0This command will run
tcpdumpwith the following options:-nn: Disable port and protocol name lookup.-r: Read capture data from the named file.-v: Display detailed packet data.
You must specify the
-nnswitch again here, as you want to make suretcpdumpdoes not perform name lookups of either IP addresses or ports, since this can alert threat actors.This returns output data similar to the following:
As in the previous example, you can see the IP packet information along with information about the data that the packet contains.reading from file capture.pcap, link-type EN10MB (Ethernet) 20:53:27.669101 IP (tos 0x0, ttl 64, id 50874, offset 0, flags [DF], proto TCP (6), length 60) 172.17.0.2:46498 > 146.75.38.132:80: Flags [S], cksum 0x5445 (incorrect), seq 4197622953, win 65320, options [mss 1420,sackOK,TS val 610940466 ecr 0, nop,wscale 7], length 0 20:53:27.669422 IP (tos 0x0, ttl 62, id 0, offset 0, flags [DF], proto TCP (6), length 60) 146.75.38.132:80: > 172.17.0.2:46498: Flags [S.], cksum 0xc272 (correct), seq 2026312556, ack 4197622953, win 65535, options [mss 1420,sackOK,TS val 155704241 ecr 610940466, nop,wscale 9], length 0 - Use the
tcpdumpcommand to filter the extended packet data from thecapture.pcapcapture file:
example output:sudo tcpdump -nn -r capture.pcap -Xexample output
analyst@b4aade4b3e15:~$ sudo tcpdump -nn -r capture.pcap -X reading from file capture.pcap, link-type EN10MB (Ethernet) 13:51:00.530684 IP 172.18.0.2.48328 > 64.233.182.139.80: Flags [S], seq 3977332362, win 65320, options [mss 1420,sackOK,TS val 109490055 ecr 0,nop,wscale 7], length 0 0x0000: 4500 003c e327 4000 4006 b40b ac12 0002 E..<.'@.@....... 0x0010: 40e9 b68b bcc8 0050 ed11 468a 0000 0000 @......P..F..... 0x0020: a002 ff28 a3b7 0000 0204 058c 0402 080a ...(............ 0x0030: 0686 af87 0000 0000 0103 0307 ............ 13:51:00.531500 IP 64.233.182.139.80 > 172.18.0.2.48328: Flags [S.], seq 1521600211, ack 3977332363, win 65535, options [mss 1420,sackOK,TS val 4261937288 ecr 109490055,nop,wscale 8], length 0 0x0000: 4560 003c 0000 4000 7e06 58d3 40e9 b68b E`.<..@.~.X.@... 0x0010: ac12 0002 0050 bcc8 5ab1 c6d3 ed11 468b .....P..Z.....F. 0x0020: a012 ffff ddb4 0000 0204 058c 0402 080a ................ 0x0030: fe08 0088 0686 af87 0103 0308 ............ 13:51:00.531518 IP 172.18.0.2.48328 > 64.233.182.139.80: Flags [.], ack 1, win 511, options [nop,nop,TS val 109490056 ecr 4261937288], length 0 0x0000: 4500 0034 e328 4000 4006 b412 ac12 0002 E..4.(@.@....... 0x0010: 40e9 b68b bcc8 0050 ed11 468b 5ab1 c6d4 @......P..F.Z... 0x0020: 8010 01ff a3af 0000 0101 080a 0686 af88 ................ 0x0030: fe08 0088 .... 13:51:00.531593 IP 172.18.0.2.48328 > 64.233.182.139.80: Flags [P.], seq 1:86, ack 1, win 511, options [nop,nop,TS val 109490056 ecr 4261937288], length 85: HTTP: GET / HTTP/1.1 0x0000: 4500 0089 e329 4000 4006 b3bc ac12 0002 E....)@.@....... 0x0010: 40e9 b68b bcc8 0050 ed11 468b 5ab1 c6d4 @......P..F.Z... 0x0020: 8018 01ff a404 0000 0101 080a 0686 af88 ................ 0x0030: fe08 0088 4745 5420 2f20 4854 5450 2f31 ....GET./.HTTP/1 0x0040: 2e31 0d0a 486f 7374 3a20 6f70 656e 736f .1..Host:.openso 0x0050: 7572 6365 2e67 6f6f 676c 652e 636f 6d0d urce.google.com. 0x0060: 0a55 7365 722d 4167 656e 743a 2063 7572 .User-Agent:.cur 0x0070: 6c2f 372e 3634 2e30 0d0a 4163 6365 7074 l/7.64.0..Accept 0x0080: 3a20 2a2f 2a0d 0a0d 0a :.*/*.... 13:51:00.531808 IP 64.233.182.139.80 > 172.18.0.2.48328: Flags [.], ack 86, win 256, options [nop,nop,TS val 4261937289 ecr 109490056], length 0 0x0000: 4560 0034 0000 4000 7e06 58db 40e9 b68b E`.4..@.~.X.@... 0x0010: ac12 0002 0050 bcc8 5ab1 c6d4 ed11 46e0 .....P..Z.....F. 0x0020: 8010 0100 0b03 0000 0101 080a fe08 0089 ................ 0x0030: 0686 af88 .... 13:51:00.533901 IP 64.233.182.139.80 > 172.18.0.2.48328: Flags [P.], seq 1:583, ack 86, win 256, options [nop,nop,TS val 4261937291 ecr 109490056], length 582: HTTP: HTTP/1.1 301 Moved Permanently 0x0000: 4580 027a 0000 4000 7e06 5675 40e9 b68b E..z..@.~.Vu@... 0x0010: ac12 0002 0050 bcc8 5ab1 c6d4 ed11 46e0 .....P..Z.....F. 0x0020: 8018 0100 f3cd 0000 0101 080a fe08 008b ................ 0x0030: 0686 af88 4854 5450 2f31 2e31 2033 3031 ....HTTP/1.1.301 0x0040: 204d 6f76 6564 2050 6572 6d61 6e65 6e74 .Moved.Permanent 0x0050: 6c79 0d0a 4c6f 6361 7469 6f6e 3a20 6874 ly..Location:.ht 0x0060: 7470 733a 2f2f 6f70 656e 736f 7572 6365 tps://opensource 0x0070: 2e67 6f6f 676c 652f 0d0a 4372 6f73 732d .google/..Cross- 0x0080: 4f72 6967 696e 2d52 6573 6f75 7263 652d Origin-Resource- 0x0090: 506f 6c69 6379 3a20 6372 6f73 732d 6f72 Policy:.cross-or 0x00a0: 6967 696e 0d0a 436f 6e74 656e 742d 5479 igin..Content-Ty 0x00b0: 7065 3a20 7465 7874 2f68 746d 6c3b 2063 pe:.text/html;.c 0x00c0: 6861 7273 6574 3d55 5446 2d38 0d0a 582d harset=UTF-8..X- 0x00d0: 436f 6e74 656e 742d 5479 7065 2d4f 7074 Content-Type-Opt 0x00e0: 696f 6e73 3a20 6e6f 736e 6966 660d 0a44 ions:.nosniff..D 0x00f0: 6174 653a 2057 6564 2c20 3133 2053 6570 ate:.Wed,.13.Sep 0x0100: 2032 3032 3320 3133 3a35 313a 3030 2047 .2023.13:51:00.G 0x0110: 4d54 0d0a 4578 7069 7265 733a 2057 6564 MT..Expires:.Wed 0x0120: 2c20 3133 2053 6570 2032 3032 3320 3134 ,.13.Sep.2023.14 0x0130: 3a32 313a 3030 2047 4d54 0d0a 4361 6368 :21:00.GMT..Cach 0x0140: 652d 436f 6e74 726f 6c3a 2070 7562 6c69 e-Control:.publi 0x0150: 632c 206d 6178 2d61 6765 3d31 3830 300d c,.max-age=1800. 0x0160: 0a53 6572 7665 723a 2073 6666 650d 0a43 .Server:.sffe..C 0x0170: 6f6e 7465 6e74 2d4c 656e 6774 683a 2032 ontent-Length:.2 0x0180: 3233 0d0a 582d 5853 532d 5072 6f74 6563 23..X-XSS-Protec 0x0190: 7469 6f6e 3a20 300d 0a0d 0a3c 4854 4d4c tion:.0....<HTML 0x01a0: 3e3c 4845 4144 3e3c 6d65 7461 2068 7474 ><HEAD><meta.htt 0x01b0: 702d 6571 7569 763d 2263 6f6e 7465 6e74 p-equiv="content 0x01c0: 2d74 7970 6522 2063 6f6e 7465 6e74 3d22 -type".content=" 0x01d0: 7465 7874 2f68 746d 6c3b 6368 6172 7365 text/html;charse 0x01e0: 743d 7574 662d 3822 3e0a 3c54 4954 4c45 t=utf-8">.<TITLE 0x01f0: 3e33 3031 204d 6f76 6564 3c2f 5449 544c >301.Moved</TITL 0x0200: 453e 3c2f 4845 4144 3e3c 424f 4459 3e0a E></HEAD><BODY>. 0x0210: 3c48 313e 3330 3120 4d6f 7665 643c 2f48 <H1>301.Moved</H 0x0220: 313e 0a54 6865 2064 6f63 756d 656e 7420 1>.The.document. 0x0230: 6861 7320 6d6f 7665 640a 3c41 2048 5245 has.moved.<A.HRE 0x0240: 463d 2268 7474 7073 3a2f 2f6f 7065 6e73 F="https://opens 0x0250: 6f75 7263 652e 676f 6f67 6c65 2f22 3e68 ource.google/">h 0x0260: 6572 653c 2f41 3e2e 0d0a 3c2f 424f 4459 ere</A>...</BODY 0x0270: 3e3c 2f48 544d 4c3e 0d0a ></HTML>.. 13:51:00.533907 IP 172.18.0.2.48328 > 64.233.182.139.80: Flags [.], ack 583, win 507, options [nop,nop,TS val 109490058 ecr 4261937291], length 0 0x0000: 4500 0034 e32a 4000 4006 b410 ac12 0002 E..4.*@.@....... 0x0010: 40e9 b68b bcc8 0050 ed11 46e0 5ab1 c91a @......P..F.Z... 0x0020: 8010 01fb a3af 0000 0101 080a 0686 af8a ................ 0x0030: fe08 008b .... 13:51:00.535313 IP 172.18.0.2.48328 > 64.233.182.139.80: Flags [F.], seq 86, ack 583, win 507, options [nop,nop,TS val 109490060 ecr 4261937291], length 0 0x0000: 4500 0034 e32b 4000 4006 b40f ac12 0002 E..4.+@.@....... 0x0010: 40e9 b68b bcc8 0050 ed11 46e0 5ab1 c91a @......P..F.Z... 0x0020: 8011 01fb a3af 0000 0101 080a 0686 af8c ................ 0x0030: fe08 008b .... 13:51:00.535704 IP 64.233.182.139.80 > 172.18.0.2.48328: Flags [F.], seq 583, ack 87, win 256, options [nop,nop,TS val 4261937292 ecr 109490060], length 0 0x0000: 4580 0034 0000 4000 7e06 58bb 40e9 b68b E..4..@.~.X.@... 0x0010: ac12 0002 0050 bcc8 5ab1 c91a ed11 46e1 .....P..Z.....F. 0x0020: 8011 0100 08b4 0000 0101 080a fe08 008c ................ 0x0030: 0686 af8c .... analyst@b4aade4b3e15:~$This command will run
tcpdumpwith the following options:-nn: Disable port and protocol name lookup.-r: Read capture data from the named file.-X: Display the hexadecimal and ASCII output format packet data. Security analysts can analyze hexadecimal and ASCII output to detect patterns or anomalies during malware analysis or forensic analysis.
Activity: Research network protocol analyzers
i probably legally cant give you anything coz its an activity
but here is the gist
In this activity, you'll focus on the two network protocol analyzers: Wireshark and tcpdump. Your goal is to gain a basic understanding of the Wireshark and tcpdump, how they work, and what their features are.
As you've learned, a network protocol analyzer (packet sniffer) is a tool designed to capture and analyze data traffic within a network. Network protocol analyzers help security analysts examine and understand the network traffic flows.
Be sure to complete this activity before moving on. The next course item will provide you with a completed exemplar to compare to your own work.
theres a venn diagram
just make a similarities chart lol
if you cant figure it out heres a chat gpt answer to the question
GPT ANSWER
Lord Naruzkurai,
Both TCPdump and Wireshark are network analysis tools, but they serve different needs & operate in different contexts. Below are some of the similarities they share:
Packet Capturing:
- Core Functionality: Both TCPdump and Wireshark can capture packets traveling over a network.
- Libpcap: They both use the libpcap library for packet capturing, which makes them highly compatible in terms of the data they can capture.
- Filters: Both offer a filtering mechanism for capturing specific types of packets.
Protocols:
- Protocol Support: Both support a wide range of protocols like TCP, UDP, HTTP, FTP, etc.
- Packet Decoding: Each can decode packets into a more human-readable form, although Wireshark offers a more GUI-driven approach.
Platforms:
- Cross-Platform: Both are available for multiple platforms. TCPdump is primarily used in UNIX-like systems, while Wireshark is available for Windows, macOS, & various Linux distributions, including those you're familiar with such as Ubuntu, Arch, and RHEL9.
Analysis:
- Offline Analysis: Both can save packet data to a file (usually in pcap format) for later analysis.
- Deep Inspection: Both provide a way to look deep into packets to examine header & payload data.
Flexibility:
- Command-Line & GUI: Both tools offer command-line options. While TCPdump is primarily a command-line tool, Wireshark also provides tshark, its own command-line interface.
- Scripting: Both can be scripted & automated to some extent, useful for CyberSec tasks and ethical hacking.
Real-Time & Post-Capture:
- Real-Time Analysis: Both allow real-time packet analysis, although Wireshark offers more detail in an easier-to-read format.
- Post-Capture Filters: Both allow filtering packets after they have been captured.
Wrap-up; Terms and definitions from Course 6, Module 2
Glossary terms from module 2
Command and control (C2): The techniques used by malicious actors to maintain communications with compromised systems
Command-line interface (CLI): A text-based user interface that uses commands to interact with the computer
Data exfiltration: Unauthorized transmission of data from a system
Data packet: A basic unit of information that travels from one device to another within a network
Indicators of compromise (IoC): Observable evidence that suggests signs of a potential security incident
Internet Protocol (IP): A set of standards used for routing and addressing data packets as they travel between devices on a network
Intrusion detection systems (IDS): An application that monitors system activity and alerts on possible intrusions
Media Access Control (MAC) Address: A unique alphanumeric identifier that is assigned to each physical device on a network
National Institute of Standards and Technology (NIST) Incident Response Lifecycle: A framework for incident response consisting of four phases: Preparation; Detection and Analysis; Containment, Eradication and Recovery; and Post-incident activity
Network data: The data that’s transmitted between devices on a network
Network protocol analyzer (packet sniffer): A tool designed to capture and analyze data traffic within a network
Network traffic: The amount of data that moves across a network
Network Interface Card (NIC): hardware that connects computers to a network
Packet capture (p-cap): A file containing data packets intercepted from an interface or network
Packet sniffing: The practice of capturing and inspecting data packets across a network
Playbook: A manual that provides details about any operational action
Root user (or superuser): A user with elevated privileges to modify the system
Sudo: A command that temporarily grants elevated permissions to specific users
tcpdump: A command-line network protocol analyzer
Wireshark: An open-source network protocol analyzer
Welcome to module 3 ; The detection and analysis phase of the lifecycle
The detection and analysis phase of the lifecycle
Cybersecurity incident detection methods
Security analysts use detection tools to help them discover threats, but there are additional methods of detection that can be used as well.
Previously, you learned about how detection tools can identify attacks like data exfiltration. In this reading, you’ll be introduced to different detection methods that organizations can employ to discover threats.
Methods of detection
During the Detection and Analysis Phase of the incident response lifecycle, security teams are notified of a possible incident and work to investigate and verify the incident by collecting and analyzing data. As a reminder, detection refers to the prompt discovery of security events and analysis involves the investigation and validation of alerts.
As you’ve learned, an intrusion detection system (IDS) can detect possible intrusions and send out alerts to security analysts to investigate the suspicious activity. Security analysts can also use security information and event management (SIEM) tools to detect, collect, and analyze security data.
You’ve also learned that there are challenges with detection. Even the best security teams can fail to detect real threats for a variety of reasons. For example, detection tools can only detect what security teams configure them to monitor. If they aren’t properly configured, they can fail to detect suspicious activity, leaving systems vulnerable to attack. It’s important for security teams to use additional methods of detection to increase their coverage and accuracy.
Threat hunting
Threats evolve and attackers advance their tactics and techniques. Automated, technology-driven detection can be limited in keeping up to date with the evolving threat landscape. Human-driven detection like threat hunting combines the power of technology with a human element to discover hidden threats left undetected by detection tools.
Threat hunting is the proactive search for threats on a network. Security professionals use threat hunting to uncover malicious activity that was not identified by detection tools and as a way to do further analysis on detections. Threat hunting is also used to detect threats before they cause damage. For example, fileless malware is difficult for detection tools to identify. It’s a form of malware that uses sophisticated evasion techniques such as hiding in memory instead of using files or applications, allowing it to bypass traditional methods of detection like signature analysis. With threat hunting, the combination of active human analysis and technology is used to identify threats like fileless malware.
Note: Threat hunting specialists are known as threat hunters. Threat hunters perform research on emerging threats and attacks and then determine the probability of an organization being vulnerable to a particular attack. Threat hunters use a combination of threat intelligence, indicators of compromise, indicators of attack, and machine learning to search for threats in an organization.
Threat intelligence
Organizations can improve their detection capabilities by staying updated on the evolving threat landscape and understanding the relationship between their environment and malicious actors. One way to understand threats is by using threat intelligence, which is evidence-based threat information that provides context about existing or emerging threats.
Threat intelligence can come from private or public sources like:
-
Industry reports: These often include details about attacker's tactics, techniques, and procedures (TTP).
-
Government advisories: Similar to industry reports, government advisories include details about attackers' TTP.
-
Threat data feeds: Threat data feeds provide a stream of threat-related data that can be used to help protect against sophisticated attackers like advanced persistent threats (APTs). APTs are instances when a threat actor maintains unauthorized access to a system for an extended period of time. The data is usually a list of indicators like IP addresses, domains, and file hashes.
It can be difficult for organizations to efficiently manage large volumes of threat intelligence. Organizations can leverage a threat intelligence platform (TIP) which is an application that collects, centralizes, and analyzes threat intelligence from different sources. TIPs provide a centralized platform for organizations to identify and prioritize relevant threats and improve their security posture.
Note: Threat intelligence data feeds are best used to add context to detections. They should not drive detections completely and should be assessed before applied to an organization.
Cyber deception
Cyber deception involves techniques that deliberately deceive malicious actors with the goal of increasing detection and improving defensive strategies.
Honeypots are an example of an active cyber defense mechanism that uses deception technology. Honeypots are systems or resources that are created as decoys vulnerable to attacks with the purpose of attracting potential intruders. For example, having a fake file labeled Client Credit Card Information - 2022 can be used to capture the activity of malicious actors by tricking them into accessing the file because it appears to be legitimate. Once a malicious actor tries to access this file, security teams are alerted.
Key takeaways
Various detection methods can be implemented to identify and locate security events in an environment. It’s essential for organizations to use a variety of detection methods, tools, and technologies to adapt to the ever evolving threat landscape and better protect assets.
Resources for more information
If you would like to explore more on threat hunting and threat intelligence, here are some resources:
-
An informational repository about threat hunting fromThe ThreatHunting Project
-
Research on state-sponsored hackersfrom Threat Analysis Group (TAG)
MK: Changes in the cybersecurity industry
Indicators of compromise
In this reading, you’ll be introduced to the concept of the Pyramid of Pain and you'll explore examples of the different types of indicators of compromise. Understanding and applying this concept helps organizations improve their defense and reduces the damage an incident can cause.
Indicators of compromise
Indicators of compromise (IoCs) are observable evidence that suggests signs of a potential security incident. IoCs chart specific pieces of evidence that are associated with an attack, like a file name associated with a type of malware. You can think of an IoC as evidence that points to something that's already happened, like noticing that a valuable has been stolen from inside of a car.
Indicators of attack (IoA) are the series of observed events that indicate a real-time incident. IoAs focus on identifying the behavioral evidence of an attacker, including their methods and intentions.
Essentially, IoCs help to identify the who and what of an attack after it's taken place, while IoAs focus on finding the why and how of an ongoing or unknown attack. For example, observing a process that makes a network connection is an example of an IoA. The filename of the process and the IP address that the process contacted are examples of the related IoCs.
Note: Indicators of compromise are not always a confirmation that a security incident has happened. IoCs may be the result of human error, system malfunctions, and other reasons not related to security.
Pyramid of Pain
Not all indicators of compromise are equal in the value they provide to security teams. It’s important for security professionals to understand the different types of indicators of compromise so that they can quickly and effectively detect and respond to them. This is why security researcher David J. Bianco created the concept of the Pyramid of Pain
, with the goal of improving how indicators of compromise are used in incident detection.

The Pyramid of Pain captures the relationship between indicators of compromise and the level of difficulty that malicious actors experience when indicators of compromise are blocked by security teams. It lists the different types of indicators of compromise that security professionals use to identify malicious activity.
Each type of indicator of compromise is separated into levels of difficulty. These levels represent the “pain” levels that an attacker faces when security teams block the activity associated with the indicator of compromise. For example, blocking an IP address associated with a malicious actor is labeled as easy because malicious actors can easily use different IP addresses to work around this and continue with their malicious efforts. If security teams are able to block the IoCs located at the top of the pyramid, the more difficult it becomes for attackers to continue their attacks. Here’s a breakdown of the different types of indicators of compromise found in the Pyramid of Pain.
-
Hash values: Hashes that correspond to known malicious files. These are often used to provide unique references to specific samples of malware or to files involved in an intrusion.
-
IP addresses: An internet protocol address like 192.168.1.1
-
Domain names: A web address such as www.google.com
-
Network artifacts: Observable evidence created by malicious actors on a network. For example, information found in network protocols such as User-Agent strings.
-
Host artifacts: Observable evidence created by malicious actors on a host. A host is any device that’s connected on a network. For example, the name of a file created by malware.
-
Tools: Software that’s used by a malicious actor to achieve their goal. For example, attackers can use password cracking tools like John the Ripper to perform password attacks to gain access into an account.
-
Tactics, techniques, and procedures (TTPs): This is the behavior of a malicious actor. Tactics refer to the high-level overview of the behavior. Techniques provide detailed descriptions of the behavior relating to the tactic. Procedures are highly detailed descriptions of the technique. TTPs are the hardest to detect.
Key takeaways
Indicators of compromise and indicators of attack are valuable sources of information for security professionals when it comes to detecting incidents. The Pyramid of Pain is a concept that can be used to understand the different types of indicators of compromise and the value they have in detecting and stopping malicious activity.
Analyze indicators of compromise with investigative tools
So far, you've learned about the different types of detection methods that can be used to detect security incidents. This reading explores how investigative tools can be used during investigations to analyze suspicious indicators of compromise (IoCs) and build context around alerts. Remember, an IoC is observable evidence that suggests signs of a potential security incident.
Adding context to investigations
You've learned about the Pyramid of Pain which describes the relationship between indicators of compromise and the level of difficulty that malicious actors experience when indicators of compromise are blocked by security teams. You also learned about different types of IoCs, but as you know, not all IoCs are equal. Malicious actors can manage to evade detection and continue compromising systems despite having their IoC-related activity blocked or limited.
For example, identifying and blocking a single IP address associated with malicious activity does not provide a broader insight on an attack, nor does it stop a malicious actor from continuing their activity. Focusing on a single piece of evidence is like fixating on a single section of a painting: You miss out on the bigger picture.

Security analysts need a way to expand the use of IoCs so that they can add context to alerts. Threat intelligence is evidence-based threat information that provides context about existing or emerging threats. By accessing additional information related to IoCs, security analysts can expand their viewpoint to observe the bigger picture and construct a narrative that helps inform their response actions.

By adding context to an IoC—for instance, identifying other artifacts related to the suspicious IP address, such as suspicious network communications or unusual processes—security teams can start to develop a detailed picture of a security incident. This context can help security teams detect security incidents faster and take a more informed approach in their response.
The power of crowdsourcing
Crowdsourcing is the practice of gathering information using public input and collaboration. Threat intelligence platforms use crowdsourcing to collect information from the global cybersecurity community. Traditionally, an organization's response to incidents was performed in isolation. A security team would receive and analyze an alert, and then work to remediate it without additional insights on how to approach it. Without crowdsourcing, attackers can perform the same attacks against multiple organizations.
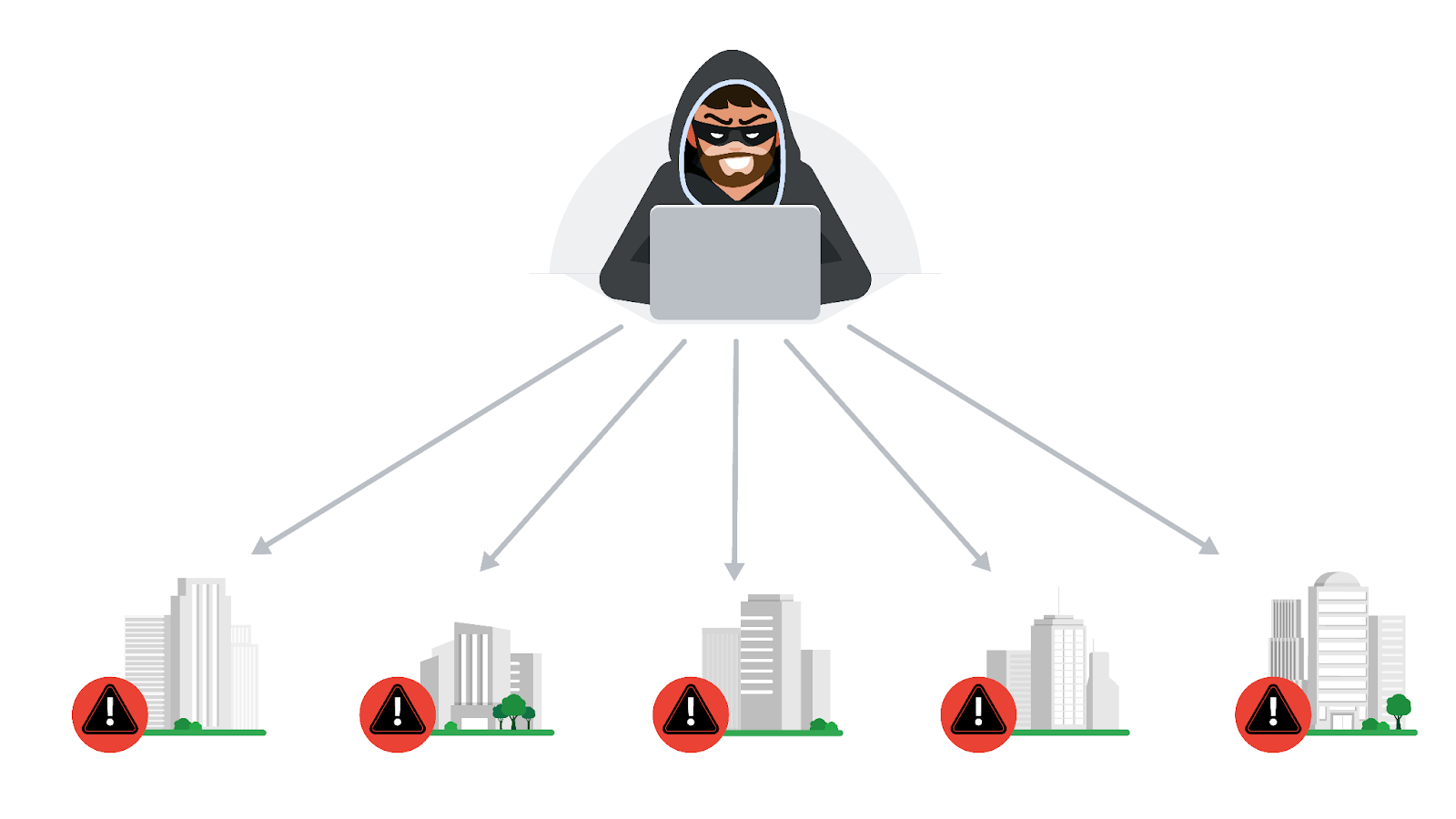
With crowdsourcing, organizations harness the knowledge of millions of other cybersecurity professionals, including cybersecurity product vendors, government agencies, cloud providers, and more. Crowdsourcing allows people and organizations from the global cybersecurity community to openly share and access a collection of threat intelligence data, which helps to continuously improve detection technologies and methodologies.
Examples of information-sharing organizations include Information Sharing and Analysis Centers (ISACs), which focus on collecting and sharing sector-specific threat intelligence to companies within specific industries like energy, healthcare, and others. Open-source intelligence (OSINT) is the collection and analysis of information from publicly available sources to generate usable intelligence. OSINT can also be used as a method to gather information related to threat actors, threats, vulnerabilities, and more.
This threat intelligence data is used to improve the detection methods and techniques of security products, like detection tools or anti-virus software. For example, attackers often perform the same attacks on multiple targets with the hope that one of them will be successful. Once an organization detects an attack, they can immediately publish the attack details, such as malicious files, IP addresses, or URLs, to tools like VirusTotal. This threat intelligence can then help other organizations defend against the same attack.
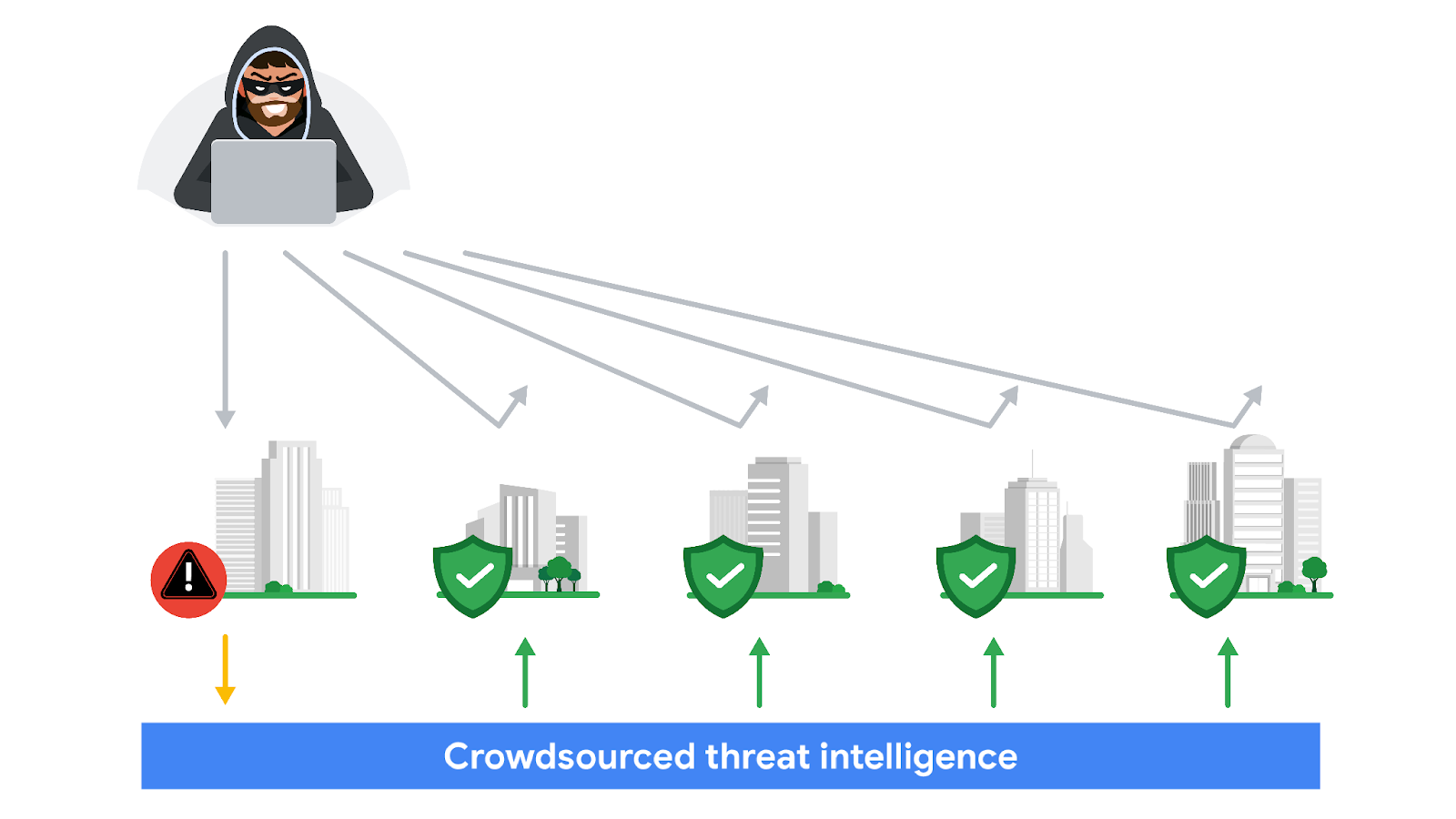
VirusTotal
is a service that allows anyone to analyze suspicious files, domains, URLs, and IP addresses for malicious content. VirusTotal also offers additional services and tools for enterprise use. This reading focuses on the VirusTotal website, which is available for free and non-commercial use.
It can be used to analyze suspicious files, IP addresses, domains, and URLs to detect cybersecurity threats such as malware. Users can submit and check artifacts, like file hashes or IP addresses, to get VirusTotal reports, which provide additional information on whether an IoC is considered malicious or not, how that IoC is connected or related to other IoCs in the dataset, and more.

Here is a breakdown of the reports summary:
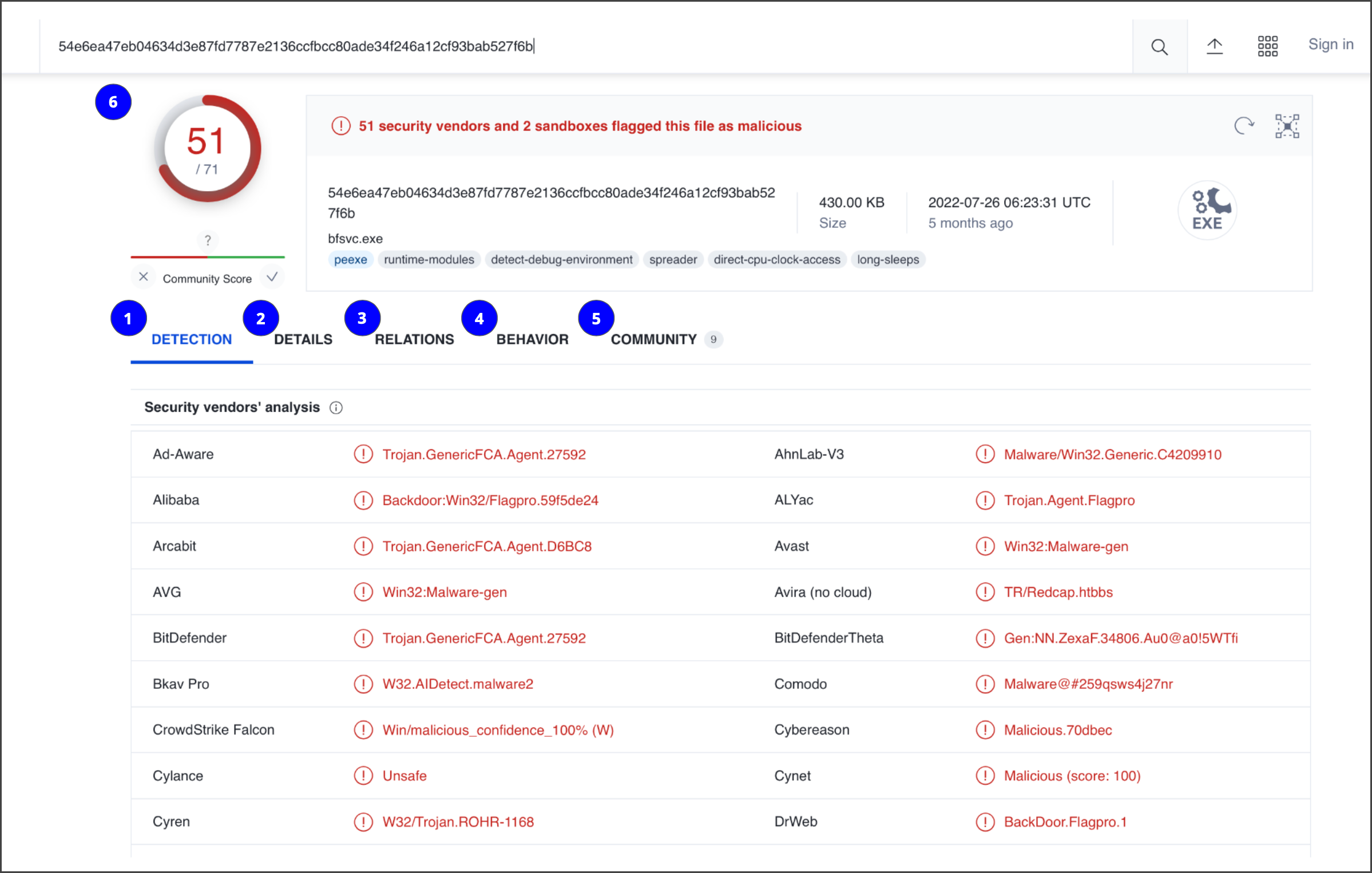
-
Detection: The Detection tab provides a list of third-party security vendors and their detection verdicts on an IoC. For example, vendors can list their detection verdict as malicious, suspicious, unsafe, and more.
-
Details: The Details tab provides additional information extracted from a static analysis of the IoC. Information such as different hashes, file types, file sizes, headers, creation time, and first and last submission information can all be found in this tab.
-
Relations: The Relations tab provides related IoCs that are somehow connected to an artifact, such as contacted URLs, domains, IP addresses, and dropped files if the artifact is an executable.
-
Behavior: The Behavior tab contains information related to the observed activity and behaviors of an artifact after executing it in a controlled or sandboxed environment. This information includes tactics and techniques detected, network communications, registry and file systems actions, processes, and more.
-
Community: The Community tab is where members of the VirusTotal community, such as security professionals or researchers, can leave comments and insights about the IoC.
-
Vendors’ ratio and community score: The score displayed at the top of the report is the vendors’ ratio. The vendors’ ratio shows how many security vendors have flagged the IoC as malicious overall. Below this score, there is also the community score, based on the inputs of the VirusTotal community. The more detections a file has and the higher its community score is, the more likely that the file is malicious.
Note: Data uploaded to VirusTotal will be publicly shared with the entire VirusTotal community. Be careful of what you submit, and make sure you do not upload personal information.
| Everyday occurrence | Indicator of compromise |
| You observe a known user successfully authenticate a new device using two-factor | You discover a ransomware note on your screen and your files locked |
| You observe a user install a verified software program | You find a USB drive plugged into an unsupervised, unlocked laptop |
|
You observe an authorized administrator adjust user permissions during working hours
|
You observe the creation of new administrative users outside of working hours |
|
You observe users logging in from an unknown geographical location
|
Other tools
There are other investigative tools that can be used to analyze IoCs. These tools can also share the data that's uploaded to them to the security community.
Jotti malware scan
is a free service that lets you scan suspicious files with several antivirus programs. There are some limitations to the number of files that you can submit.
Urlscan.io
is a free service that scans and analyzes URLs and provides a detailed report summarizing the URL information.
CAPE Sandbox
is an open source service used to automate the analysis of suspicious files. Using an isolated environment, malicious files such as malware are analyzed and a comprehensive report outlines the malware behavior.
MalwareBazaar
is a free repository for malware samples. Malware samples are a great source of threat intelligence that can be used for research purposes.
Key takeaways
As a security analyst, you'll analyze IoCs. It's important to understand how adding context to investigations can help improve detection capabilities and make informed and effective decisions.
Analyze indicators of compromise with investigative tools
So far, you've learned about the different types of detection methods that can be used to detect security incidents. This reading explores how investigative tools can be used during investigations to analyze suspicious indicators of compromise (IoCs) and build context around alerts. Remember, an IoC is observable evidence that suggests signs of a potential security incident.
Adding context to investigations
You've learned about the Pyramid of Pain which describes the relationship between indicators of compromise and the level of difficulty that malicious actors experience when indicators of compromise are blocked by security teams. You also learned about different types of IoCs, but as you know, not all IoCs are equal. Malicious actors can manage to evade detection and continue compromising systems despite having their IoC-related activity blocked or limited.
For example, identifying and blocking a single IP address associated with malicious activity does not provide a broader insight on an attack, nor does it stop a malicious actor from continuing their activity. Focusing on a single piece of evidence is like fixating on a single section of a painting: You miss out on the bigger picture.

Security analysts need a way to expand the use of IoCs so that they can add context to alerts. Threat intelligence is evidence-based threat information that provides context about existing or emerging threats. By accessing additional information related to IoCs, security analysts can expand their viewpoint to observe the bigger picture and construct a narrative that helps inform their response actions.

By adding context to an IoC—for instance, identifying other artifacts related to the suspicious IP address, such as suspicious network communications or unusual processes—security teams can start to develop a detailed picture of a security incident. This context can help security teams detect security incidents faster and take a more informed approach in their response.
The power of crowdsourcing
Crowdsourcing is the practice of gathering information using public input and collaboration. Threat intelligence platforms use crowdsourcing to collect information from the global cybersecurity community. Traditionally, an organization's response to incidents was performed in isolation. A security team would receive and analyze an alert, and then work to remediate it without additional insights on how to approach it. Without crowdsourcing, attackers can perform the same attacks against multiple organizations.

With crowdsourcing, organizations harness the knowledge of millions of other cybersecurity professionals, including cybersecurity product vendors, government agencies, cloud providers, and more. Crowdsourcing allows people and organizations from the global cybersecurity community to openly share and access a collection of threat intelligence data, which helps to continuously improve detection technologies and methodologies.
Examples of information-sharing organizations include Information Sharing and Analysis Centers (ISACs), which focus on collecting and sharing sector-specific threat intelligence to companies within specific industries like energy, healthcare, and others. Open-source intelligence (OSINT) is the collection and analysis of information from publicly available sources to generate usable intelligence. OSINT can also be used as a method to gather information related to threat actors, threats, vulnerabilities, and more.
This threat intelligence data is used to improve the detection methods and techniques of security products, like detection tools or anti-virus software. For example, attackers often perform the same attacks on multiple targets with the hope that one of them will be successful. Once an organization detects an attack, they can immediately publish the attack details, such as malicious files, IP addresses, or URLs, to tools like VirusTotal. This threat intelligence can then help other organizations defend against the same attack.

VirusTotal
is a service that allows anyone to analyze suspicious files, domains, URLs, and IP addresses for malicious content. VirusTotal also offers additional services and tools for enterprise use. This reading focuses on the VirusTotal website, which is available for free and non-commercial use.
It can be used to analyze suspicious files, IP addresses, domains, and URLs to detect cybersecurity threats such as malware. Users can submit and check artifacts, like file hashes or IP addresses, to get VirusTotal reports, which provide additional information on whether an IoC is considered malicious or not, how that IoC is connected or related to other IoCs in the dataset, and more.

Here is a breakdown of the reports summary:

-
Detection: The Detection tab provides a list of third-party security vendors and their detection verdicts on an IoC. For example, vendors can list their detection verdict as malicious, suspicious, unsafe, and more.
-
Details: The Details tab provides additional information extracted from a static analysis of the IoC. Information such as different hashes, file types, file sizes, headers, creation time, and first and last submission information can all be found in this tab.
-
Relations: The Relations tab provides related IoCs that are somehow connected to an artifact, such as contacted URLs, domains, IP addresses, and dropped files if the artifact is an executable.
-
Behavior: The Behavior tab contains information related to the observed activity and behaviors of an artifact after executing it in a controlled or sandboxed environment. This information includes tactics and techniques detected, network communications, registry and file systems actions, processes, and more.
-
Community: The Community tab is where members of the VirusTotal community, such as security professionals or researchers, can leave comments and insights about the IoC.
-
Vendors’ ratio and community score: The score displayed at the top of the report is the vendors’ ratio. The vendors’ ratio shows how many security vendors have flagged the IoC as malicious overall. Below this score, there is also the community score, based on the inputs of the VirusTotal community. The more detections a file has and the higher its community score is, the more likely that the file is malicious.
Note: Data uploaded to VirusTotal will be publicly shared with the entire VirusTotal community. Be careful of what you submit, and make sure you do not upload personal information.
Other tools
There are other investigative tools that can be used to analyze IoCs. These tools can also share the data that's uploaded to them to the security community.
Jotti malware scan
is a free service that lets you scan suspicious files with several antivirus programs. There are some limitations to the number of files that you can submit.
Urlscan.io
is a free service that scans and analyzes URLs and provides a detailed report summarizing the URL information.
CAPE Sandbox
is an open source service used to automate the analysis of suspicious files. Using an isolated environment, malicious files such as malware are analyzed and a comprehensive report outlines the malware behavior.
MalwareBazaar
is a free repository for malware samples. Malware samples are a great source of threat intelligence that can be used for research purposes.
Key takeaways
As a security analyst, you'll analyze IoCs. It's important to understand how adding context to investigations can help improve detection capabilities and make informed and effective decisions.
The benefits of documentation
Document evidence with chain of custody forms
Best practices for effective documentation
Documentation is any form of recorded content that is used for a specific purpose, and it is essential in the field of security. Security teams use documentation to support investigations, complete tasks, and communicate findings. This reading explores the benefits of documentation and provides you with a list of common practices to help you create effective documentation in your security career.
Documentation benefits
You’ve already learned about many types of security documentation, including playbooks, final reports, and more. As you’ve also learned, effective documentation has three benefits:
-
Transparency
-
Standardization
-
Clarity
Transparency
In security, transparency is critical for demonstrating compliance with regulations and internal processes, meeting insurance requirements, and for legal proceedings. Chain of custody is the process of documenting evidence possession and control during an incident lifecycle. Chain of custody is an example of how documentation produces transparency and an audit trail.
Standardization
Standardization through repeatable processes and procedures supports continuous improvement efforts, helps with knowledge transfer, and facilitates the onboarding of new team members. Standards are references that inform how to set policies.
You have learned how NIST provides various security frameworks that are used to improve security measures. Likewise, organizations set up their own standards to meet their business needs. An example of documentation that establishes standardization is an incident response plan, which is a document that outlines the procedures to take in each step of incident response. Incident response plans standardize an organization’s response process by outlining procedures in advance of an incident. By documenting an organization’s incident response plan, you create a standard that people follow, maintaining consistency with repeatable processes and procedures.
Clarity
Ideally, all documentation provides clarity to its audience. Clear documentation helps people quickly access the information they need so they can take necessary action. Security analysts are required to document the reasoning behind any action they take so that it’s clear to their team why an alert was escalated or closed.
Best practices
As a security professional, you’ll need to apply documentation best practices in your career. Here are some general guidelines to remember:
Know your audience
Before you start creating documentation, consider your audience and their needs. For instance, an incident summary written for a security operations center (SOC) manager will be written differently than one that's drafted for a chief executive officer (CEO). The SOC manager can understand technical security language but a CEO might not. Tailor your document to meet your audience’s needs.
Be concise
You might be tasked with creating long documentation, such as a report. But when documentation is too long, people can be discouraged from using it. To ensure that your documentation is useful, establish the purpose immediately. This helps people quickly identify the objective of the document. For example, executive summaries outline the major facts of an incident at the beginning of a final report. This summary should be brief so that it can be easily skimmed to identify the key findings.
Update regularly
In security, new vulnerabilities are discovered and exploited constantly. Documentation must be regularly reviewed and updated to keep up with the evolving threat landscape. For example, after an incident has been resolved, a comprehensive review of the incident can identify gaps in processes and procedures that require changes and updates. By regularly updating documentation, security teams stay well informed and incident response plans stay updated.
Key takeaways
Effective documentation produces benefits for everyone in an organization. Knowing how to create documentation is an essential skill to have as a security analyst. As you continue in your journey to become a security professional, be sure to consider these practices for creating effective documentation.
The value of cybersecurity playbooks
Generic Phishing Playbook Version 1.0
links to original google doc
Step 1: Receive phishing alert 2
Step 3.0: Does the email contain any links or attachments? 3
Step 3.1: Are the links or attachments malicious? 3
Step 3.2: Update the alert ticket and escalate 3
Step 4: Close the alert ticket 3
Phishing Flowchart (Version 1.0) 4
Purpose
To help level-one SOC analysts provide an appropriate and timely response to a phishing incident
Using this playbook
Follow the steps in this playbook in the order in which they are listed. Note that steps may overlap.
Step 1: Receive phishing alert
The process begins when you receive an alert ticket indicating that a phishing attempt has been detected.
Step 2: Evaluate the alert
Upon receiving the alert, investigate the alert details and any relevant log information. Here is a list of some of the information you should be evaluating:
-
Alert severity
-
Low: Does not require escalation
-
Medium: May require escalation
High: Requires immediate escalation to the appropriate security personnel
Receiver details
-
The receiver’s email address
-
The receiver’s IP address
Sender details
-
The sender's email address
-
The sender's IP address
Subject line
Message body
Attachments or links.
Note: Do not open links or attachments on your device unless you are using an authorized and isolated environment.
Step 3.0: Does the email contain any links or attachments?
Phishing emails can contain malicious attachments or links that are attempting to gain access to systems. After examining the details of the alert, determine whether the email contains any links or attachments. If it does, do not open the attachments or links and proceed to Step 3.1. If the email does not contain any links or attachments, proceed to Step 4.
Step 3.1: Are the links or attachments malicious?
Once you've identified that the email contains attachments or links, determine whether the links or attachments are malicious. Check the reputation of the link or file attachment through its hash values using threat intelligence tools such as VirusTotal. If you've confirmed that the link or attachment is not malicious, proceed to Step 4.
Step 3.2: Update the alert ticket and escalate
If you've confirmed that the link or attachment is malicious, provide a summary of your findings and the reason you are escalating the ticket. Update the ticket status to Escalated and notify a level-two SOC analyst of the ticket escalation.
Step 4: Close the alert ticket
Update the ticket status to Closed if:
-
You've confirmed that the email does not contain any links or attachments
or
-
You've confirmed that the link or attachment is not malicious.
Include a brief summary of your investigation findings and the reason why you’ve closed the ticket.
Phishing Flowchart (Version 1.0)
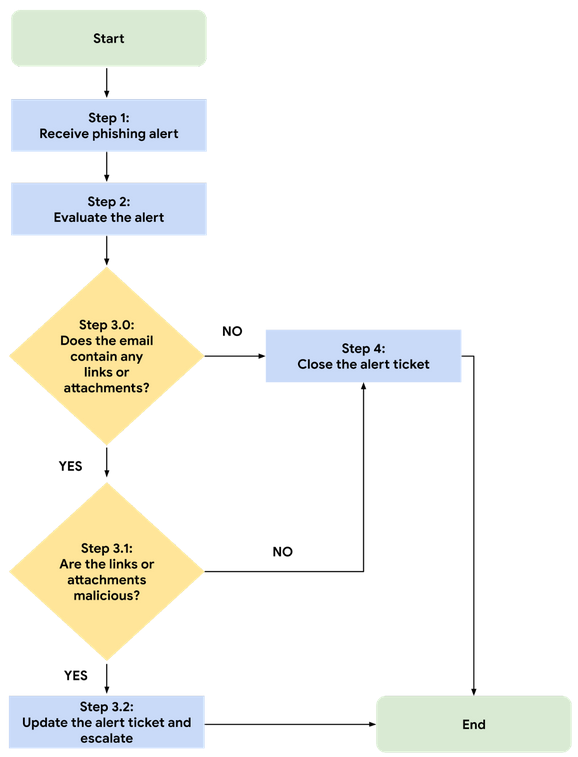
The role of triage in incident response
As you've learned, security analysts can be flooded with a large amount of alerts on any given day.
How does an analyst manage all of these alerts?
Hospital emergency departments receive a large number of patients every day.
Each patient needs medical care for a different reason, but not all patients will receive medical care immediately.
This is because hospitals have a limited number of resources available and must manage their time and energy efficiently.
They do this through a process known as triage.
In medicine, triage is used to categorize patients based on the urgency of their conditions.
For example, patients with a life-threatening condition such as a heart attack will receive immediate medical attention, but a patient with a non-life threatening condition like a broken finger may have to wait before they see a doctor.
Triage helps to manage limited resources so that hospital staff can give immediate attention to patients with the most urgent conditions.
Triage is also used in security.
Before an alert gets escalated, it goes through a triage process, which prioritizes incidents according to their level of importance or urgency.
Similar to hospital emergency departments, security teams have limited resources available to dedicate to incident response.
Not all incidents are the same, and some may involve an urgent response.
Incidents are triaged according to the threat they pose to the confidentiality, integrity, and availability of systems.
For example, an incident involving ransomware requires immediate response.
This is because ransomware may cause financial, reputational, and operational damage.
Ransomware is a higher priority than an incident like an employee receiving a phishing email.
When does triage happen?
Once an incident is detected and an alert gets sent out, triage begins.
As a security analyst, you'll identify the different types of alerts, and then prioritize them according to urgency.
The triage process generally looks like this.
First, you'll receive and assess the alert to determine if it's a false positive and whether it's related to an existing incident.
If it's a true positive, you'll assign priority on the alert based on the organization's policy and guidelines.
The priority level defines how the organization's security team will respond to the incident.
Finally, you'll investigate the alert and collect and analyze any evidence associated with the alert, such as system logs.
As an analyst, you'll want to ensure that you complete a thorough analysis so that you have enough information to make an informed decision about your findings.
For example, say that you received an alert for a failed user login attempt.
You'll need to add context to your investigation to determine if it's malicious.
You can do so by asking questions.
Is there anything out of the ordinary associated with this alert?
Are there multiple failed login attempts?
Did the login happen outside of normal working hours?
Did the login happen outside of the network?
These questions paint a picture around the incident.
By adding context, you avoid making assumptions, which can result in incomplete or incorrect conclusions.
Now that we've covered how to triage alerts, we're ready to discuss how to respond and recover from an incident.
Let's go!
Robin: Foster cross-team collaboration
My name is Robin, and I am the program management lead for the Red Team at Google.
I would say teamwork might be the most important skill for people who work in cybersecurity.
The collaborative culture is to understand that everybody brings a unique perspective and a useful perspective and useful skills.
What it is about teamwork is that these problems are hard.
These problems are complex.
The bad actors out there are smart, they're well resourced, and they're really motivated.
So they're constantly coming up with new ways to do the activities that they want to do.
It takes people with all kinds of perspectives, all kinds of problem solving skills, all kinds of knowledge to come together to understand what has happened, and how we can defend against it.
When you're working as part of a team, one of the things to expect is that you should share information freely with your colleagues and that they'll share information freely with you.
At the beginning and in the confusing part of responding to incidents, all information is useful.
So expect to dive right in, share everything you know and listen to the things people around you say, so that we come out with the best solutions as quickly as we can.
Very soon after I got into the role that I am in now, we experienced a very significant incident.
A vulnerability was discovered in a library that was used in many, many different places on the Internet and the vulnerability was significant.
I was part of the team that came together to respond to that, and that team that came together, we set up response process that involved 24/7 coverage using our colleagues all around the world.
The end result of the amazing teamwork that we experienced was, first of all, we were able to manage the vulnerability.
But more importantly, it's the way the team came together afterward.
And it's the way people still talk about how our great team work brought us closer to our colleagues, meant that our team works better together than it did before, meant that these teamwork aspects, they're all things that we do so well now.
We all feel like we've been through something together and that we came out stronger on the other side.
As you go through the certificate, you might learn that cybersecurity is tricky or it's hard but don't give up.
The more you learn, the more you're going to enjoy it.
So stay with it, learn everything you can, and you're going to have a great career.
The triage process
Previously, you learned that triaging is used to assess alerts and assign priority to incidents. In this reading, you'll explore the triage process and its benefits. As a security analyst, you'll be responsible for analyzing security alerts. Having the skills to effectively triage is important because it allows you to address and resolve security alerts efficiently.
Triage process
Incidents can have the potential to cause significant damage to an organization. Security teams must respond quickly and efficiently to prevent or limit the impact of an incident before it becomes too late. Triage is the prioritizing of incidents according to their level of importance or urgency. The triage process helps security teams evaluate and prioritize security alerts and allocate resources effectively so that the most critical issues are addressed first.
The triage process consists of three steps:
-
Receive and assess
-
Assign priority
-
Collect and analyze
Receive and assess
During this first step of the triage process, a security analyst receives an alert from an alerting system like an intrusion detection system (IDS). You might recall that an IDS is an application that monitors system activity and alerts on possible intrusions. The analyst then reviews the alert to verify its validity and ensure they have a complete understanding of the alert.
This involves gathering as much information as possible about the alert, including details about the activity that triggered the alert, the systems and assets involved, and more. Here are some questions to consider when verifying the validity of an alert:
-
Is the alert a false positive? Security analysts must determine whether the alert is a genuine security concern or a false positive, or an alert that incorrectly detects the presence of a threat.
-
Was this alert triggered in the past? If so, how was it resolved? The history of an alert can help determine whether the alert is a new or recurring issue.
-
Is the alert triggered by a known vulnerability? If an alert is triggered by a known vulnerability, security analysts can leverage existing knowledge to determine an appropriate response and minimize the impact of the vulnerability.
-
What is the severity of the alert? The severity of an alert can help determine the priority of the response so that critical issues are quickly escalated.
Assign priority
Once the alert has been properly assessed and verified as a genuine security issue, it needs to be prioritized accordingly. Incidents differ in their impact, size, and scope, which affects the response efforts. To manage time and resources, security teams must prioritize how they respond to various incidents because not all incidents are equal. Here are some factors to consider when determining the priority of an incident:
-
Functional impact: Security incidents that target information technology systems impact the service that these systems provide to its users. For example, a ransomware incident can severely impact the confidentiality, availability, and integrity of systems. Data can be encrypted or deleted, making it completely inaccessible to users. Consider how an incident impacts the existing business functionality of the affected system.
-
Information impact: Incidents can affect the confidentiality, integrity, and availability of an organization’s data and information. In a data exfiltration attack, malicious actors can steal sensitive data. This data can belong to third party users or organizations. Consider the effects that information compromise can have beyond the organization.
-
Recoverability: How an organization recovers from an incident depends on the size and scope of the incident and the amount of resources available. In some cases, recovery might not be possible, like when a malicious actor successfully steals proprietary data and shares it publicly. Spending time, effort, and resources on an incident with no recoverability can be wasteful. It’s important to consider whether recovery is possible and consider whether it’s worth the time and cost.
Note: Security alerts often come with an assigned priority or severity level that classifies the urgency of the alert based on a level of prioritization.
Collect and analyze
The final step of the triage process involves the security analyst performing a comprehensive analysis of the incident. Analysis involves gathering evidence from different sources, conducting external research, and documenting the investigative process. The goal of this step is to gather enough information to make an informed decision to address it. Depending on the severity of the incident, escalation to a level two analyst or a manager might be required. Level two analysts and managers might have more knowledge on using advanced techniques to address the incident.
Benefits of triage
By prioritizing incidents based on their potential impact, you can reduce the scope of impact to the organization by ensuring a timely response. Here are some benefits that triage has for security teams:
-
Resource management: Triaging alerts allows security teams to focus their resources on threats that require urgent attention. This helps team members avoid dedicating time and resources to lower priority tasks and might also reduce response time.
-
Standardized approach: Triage provides a standardized approach to incident handling. Process documentation, like playbooks, help to move alerts through an iterative process to ensure that alerts are properly assessed and validated. This ensures that only valid alerts are moved up to investigate.
Key takeaways
Triage allows security teams to prioritize incidents according to their level of importance or urgency. The triage process is important in ensuring that an organization meets their incident response goals. As a security professional, you will likely utilize triage to effectively respond to and resolve security incidents.
The containment, eradication, and recovery phase of the lifecycle
In this video, we'll discuss the third phase of the incident response lifecycle.
This phase includes the steps for how security teams contain, eradicate, and recover from an incident.
It's important to note that these steps interrelate.
Containment helps meet the goals of eradication, which helps meet the goals of recovery.
This phase of the lifecycle also integrates with the core functions of the NIST Cybersecurity Framework, Respond and Recover.
Let's begin with the first step, containment.
After an incident has been detected, it must be contained.
Containment is the act of limiting and preventing additional damage caused by an incident.
Organizations outline their containment strategies in incident response plans.
Containment strategies detail the actions that security teams should take after an incident has been detected.
Different containment strategies are used for various incident types.
For example, a common containment strategy for a malware incident on a single computer system is to isolate the affected system by disconnecting it from the network.
This prevents the spread of the malware to other systems in the network.
As a result, the incident is contained to the single compromised system, which limits any further damage.
Containment actions are the first step toward removing a threat from an environment.
Once an incident has been contained, security teams work to remove all traces of the incident through eradication.
Eradication involves the complete removal of the incident elements from all affected systems.
For example, eradication actions include performing vulnerability tests and applying patches to vulnerabilities related to the threat.
Finally, the last step of this phase in the incident response lifecycle is recovery.
Recovery is the process of returning affected systems back to normal operations.
An incident can disrupt key business operations and services.
During recovery, any services that were impacted by the incident are brought back to normal operation.
Recovery actions include: reimaging affected systems, resetting passwords, and adjusting network configurations like firewall rules.
Remember, the incident response lifecycle is cyclical.
Multiple incidents can happen across time and these incidents can be related.
Security teams may have to circle back to other phases in the lifecycle to conduct additional investigations.
Next up, we'll discuss the final phase of the lifecycle.
Meet you there.
Business continuity considerations
Previously, you learned about how security teams develop incident response plans to help ensure that there is a prepared and consistent process to quickly respond to security incidents. In this reading, you'll explore the importance that business continuity planning has in recovering from incidents.
Business continuity planning
Security teams must be prepared to minimize the impact that security incidents can have on their normal business operations. When an incident occurs, organizations might experience significant disruptions to the functionality of their systems and services. Prolonged disruption to systems and services can have serious effects, causing legal, financial, and reputational damages. Organizations can use business continuity planning so that they can remain operational during any major disruptions.
Similar to an incident response plan, a business continuity plan (BCP) is a document that outlines the procedures to sustain business operations during and after a significant disruption. A BCP helps organizations ensure that critical business functions can resume or can be quickly restored when an incident occurs.
Entry level security analysts aren't typically responsible for the development and testing of a BCP. However, it's important that you understand how BCPs provide organizations with a structured way to respond and recover from security incidents.
Note: Business continuity plans are not the same as disaster recovery plans. Disaster recovery plans are used to recover information systems in response to a major disaster. These disasters can range from hardware failure to the destruction of facilities from a natural disaster, like a flood.
Consider the impacts of ransomware to business continuity
Impacts of a security incident such as ransomware can be devastating for business operations. Ransomware attacks targeting critical infrastructure such as healthcare can have the potential to cause significant disruption. Depending on the severity of a ransomware attack, the accessibility, availability, and delivery of essential healthcare services can be impacted. For example, ransomware can encrypt data, resulting in disabled access to medical records, which prevents healthcare providers from accessing patient records. At a larger scale, security incidents that target the assets, systems, and networks of critical infrastructure can also undermine national security, economic security, and the health and safety of the public. For this reason, BCPs help to minimize interruptions to operations so that essential services can be accessed.
Recovery strategies
When an outage occurs due to a security incident, organizations must have some sort of a functional recovery plan set to resolve the issue and get systems fully operational. BCPs can include strategies for recovery that focus on returning to normal operations. Site resilience is one example of a recovery strategy.
Site resilience
Resilience is the ability to prepare for, respond to, and recover from disruptions. Organizations can design their systems to be resilient so that they can continue delivering services despite facing disruptions. An example is site resilience, which is used to ensure the availability of networks, data centers, or other infrastructure when a disruption happens. There are three types of recovery sites used for site resilience:
-
Hot sites: A fully operational facility that is a duplicate of an organization's primary environment. Hot sites can be activated immediately when an organization's primary site experiences failure or disruption.
-
Warm sites: A facility that contains a fully updated and configured version of the hot site. Unlike hot sites, warm sites are not fully operational and available for immediate use but can quickly be made operational when a failure or disruption occurs.
-
Cold sites: A backup facility equipped with some of the necessary infrastructure required to operate an organization's site. When a disruption or failure occurs, cold sites might not be ready for immediate use and might need additional work to be operational.
Key takeaways
Security incidents have the potential to seriously disrupt business operations. Having the right plans in place is essential so that organizations can continue to function. Business continuity plans help organizations understand the impact that serious security incidents can have on their operations and work to mitigate these impacts so that regular
The post-incident activity phase of the lifecycle
Now that a security team has successfully contained eradicated and recovered from an incident, their job is done, right?
Not quite.
Whether it's a new technology or a new vulnerability, there's always more to learn in the security field.
The perfect time for learning and improvement happens during the final phase of the incident response lifecycle, post-incident activity.
The post-incident activity phase entails the process of reviewing an incident to identify areas for improvement during incident handling.
During this phase of the lifecycle, different types of documentation get updated or created.
One of the critical forms of documentation that gets created is the final report.
The final report is documentation that provides a comprehensive review of an incident.
It includes a timeline and details of all events related to the incident and recommendations for future prevention.
During an incident, the goal of the security team is to focus efforts on response and recovery.
After an incident, security teams work to minimize the risk of it happening again.
One way to improve processes is to hold a lessons learned meeting.
A lessons learned meeting includes all parties involved in the incident and is generally held within two weeks after the incident.
During this meeting, the incident is reviewed to determine what happened, what actions were taken, and how well the actions worked.
The final report is also used as the main reference document during this meeting.
The goal of the discussions in a lessons learned meeting is to share ideas and information about the incident and how to improve future response efforts.
Here are some questions to ask during a lessons learned meeting: What happened?
What time did it happen?
Who discovered it?
How did it get contained?
What were the actions taken for recovery?
What could have been done differently?
Incident reviews can reveal human errors before detection and during response, whether it's a security analyst missing a step in a recovery process, or an employee clicking a link in a phishing email, resulting in the spread of malware.
Blaming someone for an action they did or didn't do should be avoided.
Instead security teams can view this as an opportunity to learn from what happened and improve.
Post-incident review
Previously, you explored the Containment, Eradication and Recovery phase of the NIST Incident Response Lifecycle. This reading explores the activities involved in the final phase of the lifecycle: Post-incident activity. As a security analyst, it's important to familiarize yourself with the activities involved in this phase because each security incident will provide you with an opportunity to learn and improve your responses to future incidents.
Post-incident activity
The Post-incident activity phase of the NIST Incident Response Lifecycle is the process of reviewing an incident to identify areas for improvement during incident handling.

Lessons learned
After an organization has successfully contained, eradicated, and recovered from an incident, the incident comes to a close. However, this doesn’t mean that the work of security professionals is complete. Incidents provide organizations and their security teams with an opportunity to learn from what happened and prioritize ways to improve the incident handling process.
This is typically done through a lessons learned meeting, also known as a post-mortem. A lessons learned meeting includes all involved parties after a major incident. Depending on the scope of an incident, multiple meetings can be scheduled to gather sufficient data. The purpose of this meeting is to evaluate the incident in its entirety, assess the response actions, and identify any areas of improvement. It provides an opportunity for an organization and its people to learn and improve, not to assign blame. This meeting should be scheduled no later than two weeks after an incident has been successfully remediated.
Not all incidents require their own lessons learned meeting; the size and severity of an incident will dictate whether the meeting is necessary. However, major incidents, such as ransomware attacks, should be reviewed in a dedicated lessons learned meeting. This meeting consists of all parties who participated in any aspect of the incident response process. Here are some examples of questions that are addressed in this meeting:
-
What happened?
-
What time did it happen?
-
Who discovered it?
-
How did it get contained?
-
What were the actions taken for recovery?
-
What could have been done differently?
Besides having the opportunity to learn from the incident, there are additional benefits to conducting a lessons learned meeting. For large organizations, lessons learned meetings offer a platform for team members across departments to share information and recommendations for future prevention.
Pro tip: Before a team hosts a lessons learned meeting, organizers should make sure all attendees come prepared. The meeting hosts typically develop and distribute a meeting agenda beforehand, which contains the topics of discussion and ensures that attendees are informed and prepared. Additionally, meeting roles should be assigned in advance, including a moderator to lead and facilitate discussion and a scribe to take meeting notes.
Recommendations
Lessons learned meetings provide opportunities for growth and improvement. For example, security teams can identify errors in response actions, gaps in processes and procedures, or ineffective security controls. A lessons learned meeting should result in a list of prioritized actions or actionable recommendations meant to improve an organization’s incident handling processes and overall security posture. This ensures that organizations are implementing the lessons they’ve learned after an incident so that they are not vulnerable to experiencing the same incident in the future. Examples of changes that can be implemented include updating and improving playbook instructions or implementing new security tools and technologies.
Final report
Throughout this course, you explored the importance that documentation has in recording details during the incident response lifecycle. At a minimum, incident response documentation should describe the incident by covering the 5 W's of incident investigation: who, what, where, why, and when. The details that are captured during incident response are important for developing additional documents during the end of the lifecycle.
One of the most essential forms of documentation that gets created during the end of an incident is the final report. The final report provides a comprehensive review of an incident. Final reports are not standardized, and their formats can vary across organizations. Additionally, multiple final reports can be created depending on the audience it’s written for. Here are some examples of common elements found in a final report:
-
Executive summary: A high-level summary of the report including the key findings and essential facts related to the incident
-
Timeline: A detailed chronological timeline of the incident that includes timestamps dating the sequence of events that led to the incident
-
Investigation: A compilation of the actions taken during the detection and analysis of the incident. For example, analysis of a network artifact such as a packet capture reveals information about what activities happen on a network.
-
Recommendations: A list of suggested actions for future prevention
Pro tip: When writing the final report, consider the audience that you’re writing the report for. Oftentimes, business executives and other non-security professionals who don’t have the expertise to understand technical details will read post-incident final reports. Considering the audience when writing a final report will help you effectively communicate the most important details.
Key takeaways
Post-incident actions represent the end of the incident response lifecycle. This phase provides the opportunity for security teams to meet, evaluate the response actions, make recommendations for improvement, and develop the final report.
Wrap-up; Terms and definitions from Course 6, Module 3
That wraps up our discussion on incident investigation and response.
Nice work on finishing up another section!
We've covered a lot here, so let's take a moment to quickly recap.
First, we revisited the detection and analysis phase of the NIST incident response lifecycle and focused on how to investigate and verify an incident.
We discussed the purpose of detection, and how indicators of compromise can be used to identify malicious activity on a system.
Next, we examined plans and processes behind the incident response, such as documentation and triage.
We also explored strategies for containing and eradicating an incident and recovering from it.
Finally, we examined the last phase of the incident lifecycle, post-incident actions.
We talked about final reports, timelines, and the value of scheduling post-incident reviews through lessons learned meetings.
As a security analyst, you'll be responsible for completing some processes involved in each phase of the incident response lifecycle.
Coming up, you'll learn about logs and have the chance to explore them using a SIEM.
Glossary terms from module 3
Analysis: The investigation and validation of alerts
Broken chain of custody: Inconsistencies in the collection and logging of evidence in the chain of custody
Business continuity plan (BCP): A document that outlines the procedures to sustain business operations during and after a significant disruption
Chain of custody: The process of documenting evidence possession and control during an incident lifecycle
Containment: The act of limiting and preventing additional damage caused by an incident
Crowdsourcing: The practice of gathering information using public input and collaboration
Detection: The prompt discovery of security events
Documentation: Any form of recorded content that is used for a specific purpose
Eradication: The complete removal of the incident elements from all affected systems
Final report: Documentation that provides a comprehensive review of an incident
Honeypot: A system or resource created as a decoy vulnerable to attacks with the purpose of attracting potential intruders
Incident response plan: A document that outlines the procedures to take in each step of incident response
Indicators of attack (IoA): The series of observed events that indicate a real-time incident
Indicators of compromise (IoC): Observable evidence that suggests signs of a potential security incident
Intrusion detection system (IDS): An application that monitors system activity and alerts on possible intrusions
Lessons learned meeting: A meeting that includes all involved parties after a major incident
Open-source intelligence (OSINT): The collection and analysis of information from publicly available sources to generate usable intelligence
Playbook: A manual that provides details about any operational action
Post-incident activity: The process of reviewing an incident to identify areas for improvement during incident handling
Recovery: The process of returning affected systems back to normal operations
Resilience: The ability to prepare for, respond to, and recover from disruptions
Standards: References that inform how to set policies
Threat hunting: The proactive search for threats on a network
Threat intelligence: Evidence-based threat information that provides context about existing or emerging threats
Triage: The prioritizing of incidents according to their level of importance or urgency
VirusTotal: A service that allows anyone to analyze suspicious files, domains, URLs, and IP addresses for malicious content
read
Welcome to module 4
History books. Receipts. Diaries.
What do all these things have in common?
They record events.
Whether it's historical events, financial transactions, or private diary entries, records preserve event details.
And having access to these details can help us in many ways.
Previously, we explored the different types of processes and procedures involved during each phase of the incident response lifecycle.
In this section, we'll direct our focus on one of the key components of incident investigation, logs and alerts.
In security, logs record event details and these details are used to support investigations.
First, you'll learn all about logs, what they are, and how they're created.
You'll also learn how to read and analyze logs.
Then, we'll revisit intrusion detection systems.
You'll explore how to interpret signatures.
You'll have an opportunity to apply what you've learned through hands-on activities using a tool called Suricata.
Finally, you'll search in SIEM tools like Splunk and Chronicle to locate events of interest and access log data.
Events are a valuable data source.
They help create context around an alert, so you can interpret the actions that took place on a system.
Knowing how to read, analyze, and connect different events will help you identify malicious behavior and protect systems from attack.
Ready?
Let's begin.
The importance of logs
Devices produced data in the form of events.
As a refresher, events are observable occurrences that happen on a networksystem or device.
This data provides visibility into an environment.
Logs are one of the key ways security professionals detect unusual ormalicious activity.
A log is a record of events that occur within an organization's systems.
System activity is recorded in what's known as a log file orcommonly called logs.
Almost every device or system can generate logs.
Logs contain multiple entries which detail information about a specific event oroccurrence.
Logs are useful to security analysts during incident investigation sincethey record details of what, where, and when an event occurred on the network.
This includes details like date, time, location, the action made, andthe names of the users or systems who performed the action.
These details offer valuable insight, not only fortroubleshooting issues related to system performance,but most importantly, for security monitoring.
Logs allow analysts to build a story andtimeline around various event occurrences to understand what exactly happened.
This is done through log analysis.
Log analysis is the process of examining logs to identify events of interest.
Since there are different sources available to get logs,an enormous volume of log data can be generated.
It's helpful to be selective in what we log, so that we can log efficiently.
For example, web applications generate a high volume of log messages, but not all of this data may be relevant to an investigation.
In fact, it may even slow things down.
Excluding specific data from being loggedhelps reduce the time spent searching through log data.
You may recall our discussion on SIEM technology.
SIEM tools provide security professionals with a high-level overview of what happens in a network.
SIEM tools do this by first collecting data from multiple data sources.
Then, the data gets aggregated or centralized in one place.
Finally, the diverse log formats get normalized orconverted into a single preferred format.
SIEM tools help process large log volumes from multiple data sources in real-time.
This allows security analysts to quickly search for log data and perform log analysis to support their investigations.
So how do logs get collected?
Software known as log forwarders collect logs from various sources and automatically forward them to a centralized log repository for storage.
Since different types of devices and systems can create logs, there are different log data sources in an environment.
These include network logs, which are generated by devices such as proxies, routers, switches, and firewalls, and
system logs, which are generated by operating systems.
There's also application logs, which are logs related to software applications, security logs, which are generated by security tools like IDS or IPS,
and lastly authentication logs, which record login attempts.
Here's an example of a network log from a router.
There are a couple of log entries here, but we'll focus on the first line.
Here, we can observe a number of fields.
First, there's an action specifying ALLOW. This means that the router's firewall settings allowed access from a specific IP address to google.com.
Next, there's a field specifying the source, which lists an IP address.
So far, the information from this log entry is telling us that network traffic to google.com from this source IP address is allowed.
The last field specifies the timestamp,
which is one of the most essential fields in a log.
We can identify the exact date and time of an action that's occurred.
This is useful for correlating multiple events to develop a timeline of the incident.
There you have it! You've analyzed your first network log. Coming up, we'll continue our discussion on logs and explore log formats.
The importance of logs
Devices produced data in the form of events.
As a refresher, events are observable occurrences that happen on a network system or device.
This data provides visibility into an environment.
Logs are one of the key ways security professionals detect unusual or malicious activity.
A log is a record of events that occur within an organization's systems.
System activity is recorded in what's known as a log file or commonly called logs.
Almost every device or system can generate logs.
Logs contain multiple entries which detail information about a specific event or occurrence.
Logs are useful to security analysts during incident investigation since they record details of what, where, and when an event occurred on the network.
This includes details like date, time, location, the action made, and the names of the users or systems who performed the action.
These details offer valuable insight, not only for troubleshooting issues related to system performance, but most importantly, for security monitoring.
Logs allow analysts to build a story and timeline around various event occurrences to understand what exactly happened.
This is done through log analysis.
Log analysis is the process of examining logs to identify events of interest.
Since there are different sources available to get logs, an enormous volume of log data can be generated.
It's helpful to be selective in what we log, so that we can log efficiently.
For example, web applications generate a high volume of log messages, but not all of this data may be relevant to an investigation.
In fact, it may even slow things down.
Excluding specific data from being logged helps reduce the time spent searching through log data.
You may recall our discussion on SIEM technology.
SIEM tools provide security professionals with a high-level overview of what happens in a network.
SIEM tools do this by first collecting data from multiple data sources.
Then, the data gets aggregated or centralized in one place.
Finally, the diverse log formats get normalized or converted into a single preferred format.
SIEM tools help process large log volumes from multiple data sources in real-time.
This allows security analysts to quickly search for log data and perform log analysis to support their investigations.
So how do logs get collected?
Software known as log forwarders collect logs from various sources and automatically forward them to a centralized log repository for storage.
Since different types of devices and systems can create logs, there are different log data sources in an environment.
These include network logs, which are generated by devices such as proxies, routers, switches, and firewalls, and system logs, which are generated by operating systems.
There's also application logs, which are logs related to software applications, security logs, which are generated by security tools like IDS or IPS, and lastly authentication logs, which record login attempts.
Here's an example of a network log from a router.
There are a couple of log entries here, but we'll focus on the first line.
Here, we can observe a number of fields.
First, there's an action specifying ALLOW.
This means that the router's firewall settings allowed access from a specific IP address to google.com.
Next, there's a field specifying the source, which lists an IP address.
So far, the information from this log entry is telling us that network traffic to google.com from this source IP address is allowed.
The last field specifies the timestamp, which is one of the most essential fields in a log.
We can identify the exact date and time of an action that's occurred.
This is useful for correlating multiple events to develop a timeline of the incident.
There you have it!
You've analyzed your first network log.
Coming up, we'll continue our discussion on logs and explore log formats.
Best practices for log collection and management
In this reading, you’ll examine some best practices related to log management, storage, and protection. Understanding the best practices related to log collection and management will help improve log searches and better support your efforts in identifying and resolving security incidents.
Logs
Data sources such as devices generate data in the form of events. A log is a record of events that occur within an organization's systems. Logs contain log entries and each entry details information corresponding to a single event that happened on a device or system. Originally, logs served the sole purpose of troubleshooting common technology issues. For example, error logs provide information about why an unexpected error occurred and help to identify the root cause of the error so that it can be fixed. Today, virtually all computing devices produce some form of logs that provide valuable insights beyond troubleshooting.
Security teams access logs from logging receivers like SIEM tools which consolidate logs to provide a central repository for log data. Security professionals use logs to perform log analysis, which is the process of examining logs to identify events of interest. Logs help uncover the details surrounding the 5 W's of incident investigation: who triggered the incident, what happened, when the incident took place, where the incident took place, and why the incident occurred.
Types of logs
Depending on the data source, different log types can be produced. Here’s a list of some common log types that organizations should record:
-
Network: Network logs are generated by network devices like firewalls, routers, or switches.
-
System: System logs are generated by operating systems like Chrome OS™, Windows, Linux, or macOS®.
-
Application: Application logs are generated by software applications and contain information relating to the events occurring within the application such as a smartphone app.
-
Security: Security logs are generated by various devices or systems such as antivirus software and intrusion detection systems. Security logs contain security-related information such as file deletion.
-
Authentication: Authentication logs are generated whenever authentication occurs such as a successful login attempt into a computer.
Log details
Generally, logs contain a date, time, location, action, and author of the action. Here is an example of an authentication log:
Login Event [05:45:15] User1 Authenticated successfully
Logs contain information and can be adjusted to contain even more information. Verbose logging records additional, detailed information beyond the default log recording. Here is an example of the same log above but logged as verbose.
Login Event [2022/11/16 05:45:15.892673] auth_performer.cc:470 User1 Authenticated successfully from device1 (192.168.1.2)
Log management
Because all devices produce logs, it can quickly become overwhelming for organizations to keep track of all the logs that are generated. To get the most value from your logs, you need to choose exactly what to log, how to access it easily, and keep it secure using log management. Log management is the process of collecting, storing, analyzing, and disposing of log data.
What to log
The most important aspect of log management is choosing what to log. Organizations are different, and their logging requirements can differ too. It's important to consider which log sources are most likely to contain the most useful information depending on your event of interest. This might be configuring log sources to reduce the amount of data they record, such as excluding excessive verbosity. Some information, including but not limited to phone numbers, email addresses, and names, form personally identifiable information (PII), which requires special handling and in some jurisdictions might not be possible to be logged.
The issue with overlogging
From a security perspective, it can be tempting to log everything. This is the most common mistake organizations make. Just because it can be logged, doesn't mean it needs to be logged. Storing excessive amounts of logs can have many disadvantages with some SIEM tools. For example, overlogging can increase storage and maintenance costs. Additionally, overlogging can increase the load on systems, which can cause performance issues and affect usability, making it difficult to search for and identify important events.
Log retention
Organizations might operate in industries with regulatory requirements. For example, some regulations require organizations to retain logs for set periods of time and organizations can implement log retention practices in their log management policy.
Organizations that operate in the following industries might need to modify their log management policy to meet regulatory requirements:
-
Public sector industries, like the Federal Information Security Modernization Act (FISMA)
-
Healthcare industries, like the Health Insurance Portability and Accountability Act of 1996 (HIPAA)
-
Financial services industries, such as the Payment Card Industry Data Security Standard (PCI DSS), the Gramm-Leach-Bliley Act (GLBA), and the Sarbanes-Oxley Act of 2002 (SOX)
Log protection
Along with management and retention, the protection of logs is vital in maintaining log integrity. It’s not unusual for malicious actors to modify logs in attempts to mislead security teams and to even hide their activity.
Storing logs in a centralized log server is a way to maintain log integrity. When logs are generated, they get sent to a dedicated server instead of getting stored on a local machine. This makes it more difficult for attackers to access logs because there is a barrier between the attacker and the log location.
Key takeaways
It's important to understand how to properly collect, store, and protect logs because they are integral to incident investigations. Having a detailed plan for log management helps improve the usefulness of logs and resource efficiency.
Rebecca: Learn new tools and technologies
I am Rebecca, I'm a security engineer at Google, and I focus in identity management.
The best part of the job is probably thinking like an attacker.
I love that part of seeing how can I break stuff, seeing a system and figuring out how can I get into it.
If I was a bad guy, what would I be wanting?
What would I be looking for?
How would I find the credentials?
How would I find the machine that's useful, and get onto it?
My first day in security, we were learning a new tool.
The whole organization was in a training, and they're like, we're going to throw you in.
It's a one week training to learn a network analyzer.
I didn't know anything about networks, let alone network security, or what this thing was going to be used for.
And so I was very overwhelmed, because I felt like I was an imposter sitting in somebody's seat who should belong there.
And learning stuff way over my head.
I pushed through it by asking a lot of questions, and setting aside that feeling like I should know things, because I've never been exposed to it at that point.
The only way I'm going to know is if I ask.
So, this course has a lot of tools, and covers a lot of information.
And it can be very easy to be overwhelmed, in fact, I probably would be as well.
There's a lot of information that you can take in.
I think of learning in a course like this, where there's a series of courses for you to learn, that it's like climbing a mountain.
You've gotten so far up the mountain, and the air gets thin, and, yes, it is difficult.
You feel overwhelmed, but you're almost to the top.
And know that when you get to the top, you're going to have an amazing view of the world.
And that's the same thing of when you finish these courses.
Your frame of mind and how you view things and your capabilities, your potential for finding new jobs, or changing careers is that much better.
Variations of logs
When you purchase an item in a store, you usually receive a receipt as a record of purchase.
The receipt breaks down the transaction information with details such as the date and time, the cashier's name, the item name, cost, and the method of payment.
But, not all store receipts look the same.
For example, receipts like automotive invoices use lots of detail when listing the items or services that were sold.
You most likely won't find this much detail from a restaurant receipt.
Despite the differences among store receipts, all receipts contain important details that are relevant to the transaction.
Logs are similar to receipts.
While receipts record purchases, logs record the events or activities that happen on a network or system.
As a security analyst, you'll be responsible for interpreting logs.
Logs come in different formats, so not all logs look the same.
But, they usually contain information like timestamps, system characteristics, like IP addresses, and a description of the event, including the action taken and who performed the action.
We know that logs can be generated from many different data sources such as network devices, operating systems, and more.
These log sources generate logs in different formats.
Some log formats are designed to be human-readable while others are machine-readable.
Some logs can be verbose, which means they contain lots of information, while some are short and simple.
Let's explore some commonly used log formats.
One of the most commonly used log formats is Syslog.
Syslog is both a protocol and a log format.
As a protocol, it transports and writes logs.
As a log format, it contains a header, followed by structured-data, and a message.
The Syslog entry includes three sections: a header, structured-data, and a message.
The header contains data fields like Timestamp, the Hostname, the Application name, and the Message ID.
The structured-data portion contains additional data information in key-value pairs.
Here, the eventSource is a key that specifies the data source of the log, which is the value Application.
Lastly, the message component contains the detailed log message about the event.
In this example, "This is a log entry!" is the message.
Let's explore another common log format you might encounter as a security analyst.
JavaScript Object Notation, more popularly known as JSON, is a text-based format designed to be easy to read and write.
It also uses key-value pairs to structure data.
Here's an example of a JSON log.
The curly brackets represent the beginning and end of an object.
The object is the data that's enclosed between the brackets.
It's organized using key-value pairs where each key has a corresponding value separated by colons.
For example, for the first line, the key is Alert and the value is Malware.
JSON is known for its simplicity and easy readability.
As a security analyst, you'll use JSON to read and write data like logs.
eXtensible Markup Language, or XML, is a language and a format used for storing and transmitting data.
Instead of key-value pairs, it uses tags and other keys to structure data.
Here, we have an example of an XML log entry with four fields: firstName, lastName, employeeID, and dateJoined, which are separated with arrows.
Finally, Comma Separated Values, or CSV, is a format that uses separators like commas to separate data values.
In this example, there are many different data fields which are separated with commas.
Now that you know about the diversity of log formats, you can focus on evaluating logs to build context around a detection.
Coming up, you'll explore how IDS signatures are used to detect, log, and alert on suspicious activity.
Overview of log file formats
You’ve learned about how logs record events that happen on a network, or system. In security, logs provide key details about activities that occurred across an organization, like who signed into an application at a specific point in time. As a security analyst, you’ll use log analysis, which is the process of examining logs to identify events of interest. It’s important to know how to read and interpret different log formats so that you can uncover the key details surrounding an event and identify unusual or malicious activity. In this reading, you’ll review the following log formats:
-
JSON
-
Syslog
-
XML
-
CSV
-
CEF
JavaScript Object Notation (JSON)
JavaScript Object Notation (JSON) is a file format that is used to store and transmit data. JSON is known for being lightweight and easy to read and write. It is used for transmitting data in web technologies and is also commonly used in cloud environments. JSON syntax is derived from JavaScript syntax. If you are familiar with JavaScript, you might recognize that JSON contains components from JavaScript including:
-
Key-value pairs
-
Commas
-
Double quotes
-
Curly brackets
-
Square brackets
Key-value pairs
A key-value pair is a set of data that represents two linked items: a key and its corresponding value. A key-value pair consists of a key followed by a colon, and then followed by a value. An example of a key-value pair is "Alert": "Malware".
Note: For readability, it is recommended that key-value pairs contain a space before or after the colon that separates the key and value.
Commas
Commas are used to separate data. For example: "Alert": "Malware", "Alert code": 1090, "severity": 10.
Double quotes
Double quotes are used to enclose text data, which is also known as a string, for example: "Alert": "Malware". Data that contains numbers is not enclosed in quotes, like this: "Alert code": 1090.
Curly brackets
Curly brackets enclose an object, which is a data type that stores data in a comma-separated list of key-value pairs. Objects are often used to describe multiple properties for a given key. JSON log entries start and end with a curly bracket. In this example, User is the object that contains multiple properties:
"User" { "id": "1234", "name": "user", "role": "engineer" }
Square brackets
Square brackets are used to enclose an array, which is a data type that stores data in a comma-separated ordered list. Arrays are useful when you want to store data as an ordered collection, for example: ["Administrators", "Users", "Engineering"].
Syslog
Syslog is a standard for logging and transmitting data. It can be used to refer to any of its three different capabilities:
-
Protocol: The syslog protocol is used to transport logs to a centralized log server for log management. It uses port 514 for plaintext logs and port 6514 for encrypted logs.
-
Service: The syslog service acts as a log forwarding service that consolidates logs from multiple sources into a single location. The service works by receiving and then forwarding any syslog log entries to a remote server.
-
Log format: The syslog log format is one of the most commonly used log formats that you will be focusing on. It is the native logging format used in Unix® systems. It consists of three components: a header, structured-data, and a message.
Syslog log example
Here is an example of a syslog entry that contains all three components: a header, followed by structured-data, and a message:
<236>1 2022-03-21T01:11:11.003Z virtual.machine.com evntslog - ID01 [user@32473 iut="1" eventSource="Application" eventID="9999"] This is a log entry!
Header
The header contains details like the timestamp; the hostname, which is the name of the machine that sends the log; the application name; and the message ID.
-
Timestamp: The timestamp in this example is 2022-03-21T01:11:11.003Z, where 2022-03-21 is the date in YYYY-MM-DD format. T is used to separate the date and the time. 01:11:11.003 is the 24-hour format of the time and includes the number of milliseconds 003. Z indicates the timezone, which is Coordinated Universal Time (UTC).
-
Hostname: virtual.machine.com
-
Application: evntslog
-
Message ID: ID01
Structured-data
The structured-data portion of the log entry contains additional logging information. This information is enclosed in square brackets and structured in key-value pairs. Here, there are three keys with corresponding values: [user@32473 iut="1" eventSource="Application" eventID="9999"].
Message
The message contains a detailed log message about the event. Here, the message is This is a log entry!.
Priority (PRI)
The priority (PRI) field indicates the urgency of the logged event and is contained with angle brackets. In this example, the priority value is <236> . Generally, the lower the priority level, the more urgent the event is.
Note: Syslog headers can be combined with JSON, and XML formats. Custom log formats also exist.
XML (eXtensible Markup Language)
XML (eXtensible Markup Language) is a language and a format used for storing and transmitting data. XML is a native file format used in Windows systems. XML syntax uses the following:
Tags
Elements
XML elements include both the data contained inside of a tag and the tags itself. All XML entries must contain at least one root element. Root elements contain other elements that sit underneath them, known as child elements.
Here is an example:
<Event> <EventID>4688</EventID> <Version>5</Version> </Event>
In this example, <Event> is the root element and contains two child elements <EventID> and <Version>. There is data contained in each respective child element.
Attributes
XML elements can also contain attributes. Attributes are used to provide additional information about elements. Attributes are included as the second part of the tag itself and must always be quoted using either single or double quotes.
For example:
<EventData>
<Data Name='SubjectUserSid'>S-2-3-11-160321</Data>
<Data Name='SubjectUserName'>JSMITH</Data>
<Data Name='SubjectDomainName'>ADCOMP</Data>
<Data Name='SubjectLogonId'>0x1cf1c12</Data>
<Data Name='NewProcessId'>0x1404</Data>
</EventData>
In the first line for this example, the tag is <Data> and it uses the attribute Name='SubjectUserSid' to describe the data enclosed in the tag S-2-3-11-160321.
CSV (Comma Separated Value)
CSV (Comma Separated Value) uses commas to separate data values. In CSV logs, the position of the data corresponds to its field name, but the field names themselves might not be included in the log. It’s critical to understand what fields the source device (like an IPS, firewall, scanner, etc.) is including in the log.
Here is an example:
2009-11-24T21:27:09.534255,ALERT,192.168.2.7, 1041,x.x.250.50,80,TCP,ALLOWED,1:2001999:9,"ET MALWARE BTGrab.com Spyware Downloading Ads",1
CEF (Common Event Format)
Common Event Format (CEF) is a log format that uses key-value pairs to structure data and identify fields and their corresponding values. The CEF syntax is defined as containing the following fields:
CEF:Version|Device Vendor|Device Product|Device Version|Signature ID|Name|Severity|Extension
Fields are all separated with a pipe character |. However, anything in the Extension part of the CEF log entry must be written in a key-value format. Syslog is a common method used to transport logs like CEF. When Syslog is used a timestamp and hostname will be prepended to the CEF message. Here is an example of a CEF log entry that details malicious activity relating to a worm infection:
Sep 29 08:26:10 host CEF:1|Security|threatmanager|1.0|100|worm successfully stopped|10|src=10.0.0.2 dst=2.1.2.2 spt=1232
Here is a breakdown of the fields:
-
Syslog Timestamp: Sep 29 08:26:10
-
Syslog Hostname: host
-
Version: CEF:1
-
Device Vendor: Security
-
Device Product: threatmanager
-
Device Version: 1.0
-
Signature ID: 100
-
Name: worm successfully stopped
-
Severity: 10
-
Extension: This field contains data written as key-value pairs. There are two IP addresses, src=10.0.0.2 and dst=2.1.2.2, and a source port number spt=1232. Extensions are not required and are optional to add.
This log entry contains details about a Security application called threatmanager that successfully stopped a worm from spreading from the internal network at 10.0.0.2 to the external network 2.1.2.2 through the port 1232. A high severity level of 10 is reported.
Note: Extensions and syslog prefix are optional to add to a CEF log.
Key takeaways
There is no standard format used in logging, and many different log formats exist. As a security analyst, you will analyze logs that originate from different sources. Knowing how to interpret different log formats will help you determine key information that you can use to support your investigations.
Resources for more information
-
To learn more about the syslog protocol including priority levels, check out The Syslog Protocol
-
.
-
If you would like to explore generating log formats, check out this open-source test data generator tool
-
.
-
To learn more about timestamp formats, check out Date and Time on the Internet: Timestamps
Security monitoring with detection tools
Detection requires data, and this data can come from various data sources.
You've already explored how different devices produce logs.
Now we'll examine how different detection technologies monitor devices and log different types of system activity, like network and endpoint telemetry.
Telemetry is the collection and transmission of data for analysis.
While logs record events occurring on systems, telemetry describes the data itself.
For example, packet captures are considered network telemetry.
For security professionals, logs and telemetry are sources of evidence that can be used to answer questions during investigations.
Previously, you learned about an intrusion detection system, or IDS.
Remember that IDS is an application that monitors activity and alerts on possible intrusions.
This includes monitoring different parts of a system or network like an endpoint.
An endpoint is any device connected on a network, such as a laptop, tablet, desktop computer, or a smartphone.
Endpoints are entry points into a network, which makes them key targets for malicious actors looking to gain unauthorized access into a system.
To monitor endpoints for threats or attacks, a host-based intrusion detection system can be used.
It's an application that monitors the activity of the host on which it's installed.
To clarify, a host is any device that communicates with other devices on a network, similar to an endpoint.
Host-based intrusion detection systems are installed as an agent on a single host, such as a laptop computer or a server.
Depending on its configuration, host-based intrusion detection systems will monitor the host on which it's installed to detect suspicious activity.
Once something has been detected, it records output as logs and an alert gets generated.
What if we wanted to monitor a network?
A network-based intrusion detection system collects and analyzes network traffic and network data.
Network-based intrusion detection systems work similar to packet sniffers because they analyze network traffic and network data on a specific point in the network.
It's common to deploy multiple IDS sensors at different points in the network to achieve adequate visibility.
When suspicious or unusual network activity is detected, the network-based intrusion detection system logs it and generates an alert.
In this example, the network-based intrusion detection system is monitoring the traffic that's both coming from and going to the internet.
Intrusion detection systems use different types of detection methods.
One of the most common methods is signature analysis.
Signature analysis is a detection method used to find events of interest.
A signature specifies a set of rules that an IDS refers to when it monitors activity.
If the activity matches the rules in the signature, the IDS logs it and sends out an alert.
For example, a signature can be written to generate an alert if a failed login on a system happens three times in a row, which suggests a possible password attack.
Before alerts are generated, the activity must be logged.
IDS technologies record the information of the devices, systems, and networks which they monitor as IDS logs.
IDS logs can then be sent, stored, and analyzed in a centralized log repository like a SIEM.
Coming up, we'll explore how to read and configure signatures.
Meet you there!
Detection tools and techniques
In this reading, you’ll examine the different types of intrusion detection system (IDS) technologies and the alerts they produce. You’ll also explore the two common detection techniques used by detection systems. Understanding the capabilities and limitations of IDS technologies and their detection techniques will help you interpret security information to identify, analyze, and respond to security events.
As you’ve learned, an intrusion detection system (IDS) is an application that monitors system activity and alerts on possible intrusions. IDS technologies help organizations monitor the activity that happens on their systems and networks to identify indications of malicious activity. Depending on the location you choose to set up an IDS, it can be either host-based or network-based.
Host-based intrusion detection system
A host-based intrusion detection system (HIDS) is an application that monitors the activity of the host on which it's installed. A HIDS is installed as an agent on a host. A host is also known as an endpoint, which is any device connected to a network like a computer or a server.
Typically, HIDS agents are installed on all endpoints and used to monitor and detect security threats. A HIDS monitors internal activity happening on the host to identify any unauthorized or abnormal behavior. If anything unusual is detected, such as the installation of an unauthorized application, the HIDS logs it and sends out an alert.
In addition to monitoring inbound and outbound traffic flows, HIDS can have additional capabilities, such as monitoring file systems, system resource usage, user activity, and more.
This diagram shows a HIDS tool installed on a computer. The dotted circle around the host indicates that it is only monitoring the local activity on the single computer on which it’s installed.

Network-based intrusion detection system
A network-based intrusion detection system (NIDS) is an application that collects and monitors network traffic and network data. NIDS software is installed on devices located at specific parts of the network that you want to monitor. The NIDS application inspects network traffic from different devices on the network. If any malicious network traffic is detected, the NIDS logs it and generates an alert.
This diagram shows a NIDS that is installed on a network. The highlighted circle around the server and computers indicates that the NIDS is installed on the server and is monitoring the activity of the computers.

Using a combination of HIDS and NIDS to monitor an environment can provide a multi-layered approach to intrusion detection and response. HIDS and NIDS tools provide a different perspective on the activity occurring on a network and the individual hosts that are connected to it. This helps provide a comprehensive view of the activity happening in an environment.
Detection techniques
Detection systems can use different techniques to detect threats and attacks. The two types of detection techniques that are commonly used by IDS technologies are signature-based analysis and anomaly-based analysis.
Signature-based analysis
Signature analysis, or signature-based analysis, is a detection method that is used to find events of interest. A signature is a pattern that is associated with malicious activity. Signatures can contain specific patterns like a sequence of binary numbers, bytes, or even specific data like an IP address.
Previously, you explored the Pyramid of Pain, which is a concept that prioritizes the different types of indicators of compromise (IoCs) associated with an attack or threat, such as IP addresses, tools, tactics, techniques, and more. IoCs and other indicators of attack can be useful for creating targeted signatures to detect and block attacks.
Different types of signatures can be used depending on which type of threat or attack you want to detect. For example, an anti-malware signature contains patterns associated with malware. This can include malicious scripts that are used by the malware. IDS tools will monitor an environment for events that match the patterns defined in this malware signature. If an event matches the signature, the event gets logged and an alert is generated.
Advantages
-
Low rate of false positives: Signature-based analysis is very efficient at detecting known threats because it is simply comparing activity to signatures. This leads to fewer false positives. Remember that a false positive is an alert that incorrectly detects the presence of a threat.
Disadvantages
-
Signatures can be evaded: Signatures are unique, and attackers can modify their attack behaviors to bypass the signatures. For example, attackers can make slight modifications to malware code to alter its signature and avoid detection.
-
Signatures require updates: Signature-based analysis relies on a database of signatures to detect threats. Each time a new exploit or attack is discovered, new signatures must be created and added to the signature database.
-
Inability to detect unknown threats: Signature-based analysis relies on detecting known threats through signatures. Unknown threats can't be detected, such as new malware families or zero-day attacks, which are exploits that were previously unknown.
Anomaly-based analysis
Anomaly-based analysis is a detection method that identifies abnormal behavior. There are two phases to anomaly-based analysis: a training phase and a detection phase. In the training phase, a baseline of normal or expected behavior must be established. Baselines are developed by collecting data that corresponds to normal system behavior. In the detection phase, the current system activity is compared against this baseline. Activity that happens outside of the baseline gets logged, and an alert is generated.
Advantages
-
Ability to detect new and evolving threats: Unlike signature-based analysis, which uses known patterns to detect threats, anomaly-based analysis can detect unknown threats.
Disadvantages
-
High rate of false positives: Any behavior that deviates from the baseline can be flagged as abnormal, including non-malicious behaviors. This leads to a high rate of false positives.
-
Pre-existing compromise: The existence of an attacker during the training phase will include malicious behavior in the baseline. This can lead to missing a pre-existing attacker.
Key takeaways
IDS technologies are an essential security tool that you will encounter in your security journey. To recap, a NIDS monitors an entire network, whereas a HIDS monitors individual endpoints. IDS technologies generate different types of alerts. Lastly, IDS technologies use different detection techniques like signature-based or anomaly-based analysis to identify malicious activity.
Grace: Security mindset in detection and response
Hi, I'm Grace, and I work in Detection and Response at Google.
When I tell people what I do, they think it's awesome, I love being able to say, my job is to detect hackers trying to hack Google.
There are people who trust us with their data that play critical roles in society, like journalists and activists, for example.
So they need to be able to have their data with us and trust that it's going to be safe.
Security mindset is about curiosity.
There's a really nice overlap between cybersecurity and computers and having that creative and logical outlet and an interest in big world matters.
What hackers are thinking, what defenders are thinking.
I'm empathizing with people looking at how information can be attained, perhaps sometimes from unusual sources.
An example of one of the craziest things that I've learned about would be how people can get information from a CPU.
Some tasks for a CPU are more difficult than others, require more energy to do multiplying numbers as an example of that, which means that the CPU is going to work harder, it's going to get hotter, it's going to be executing more functions.
So you can use that information to know things about what that CPU is doing.
From there, you can start to deduce what's happening at a given point in time.
What I recommend to people who are interested in developing a security mindset is listen to stories.
There are podcasts that have great interviews with hackers.
I recommend following the news and reading news articles about different cyber threats that are happening on in the world.
I recommend going to conferences, go to meetups, finding people that you can study with and practice with.
Even hackers are teaching each other how to hack things in forums and chat rooms.
It's not cheating to ask for help.
Another piece of advice that I have for people would be to not give up when you have roadblocks.
Studying the certificate is a really good idea, and it's really worth persevering right to the very end.
Even when it gets hard and you start feeling overwhelmed, that's okay, they're new terms.
I can guarantee that if you come back to it later, you'll be more familiar.
You'll find it easier.
Being really gentle with yourself and understanding and patient will help a lot when you're facing these challenges.
Components of a detection signature
As a security analyst, you may be tasked with writing, customizing, or testing signatures.
To do this, you'll use IDS tools.
So in this section, we'll examine signature syntax and by the end, you'll be able to read a signature.
A signature specifies detection rules.
These rules outline the types of network intrusions you want an IDS to detect.
For example, a signature can be written to detect and alert on suspicious traffic attempting to connect to a port.
Rule language differs depending on different network intrusion detection systems.
The term network intrusion detection system is often abbreviated as the acronym N-I-D-S and pronounced NIDS.
Generally, NIDS rules consists of three components: an action, a header, and rule options.
Now, let's examine each of these three components in more detail.
Typically, the action is the first item specified in a signature.
This determines the action to take if the rule criteria matches are met.
Actions differ across NIDS rule languages, but some common actions are: alert, pass, or reject.
Using our example, if a rule specifies to alert on suspicious network traffic that establishes an unusual connection to a port, the IDS will inspect the traffic packets and send out an alert.
The header defines the signature's network traffic.
These include information such as source and destination IP addresses, source and destination ports, protocols, and traffic direction.
If we want to detect an alert on suspicious traffic connecting to a port, we have to first define the source of the suspicious traffic in the header.
Suspicious traffic can originate from IP addresses outside the local network.
It can also use specific or unusual protocols.
We can specify external IP addresses and these protocols in the header.
Here's an example of how header information may appear in a basic rule.
First, we can observe that the protocol, TCP, is the first listed item in the signature.
Next, the source IP address 10.120.170.17 and the source port number is specified as being any.
The arrow in the middle of the signature indicates the direction of the network traffic.
So we know it's originating from the source IP 10.120.170.17 from any port going to the following destination IP address 133.113.202.181 and destination port 80.
The rule options lets you customize signatures with additional parameters.
There are many different options available to use.
For instance, you can set options to match the content of a network packet to detect malicious payloads.
Malicious payloads reside in a packet's data and perform malicious activity like deleting or encrypting data.
Configuring rule options helps in narrowing down network traffic, so you can find exactly what you're looking for.
Typically, rule options are separated by semi-colons and enclosed in parentheses.
In this example, we can examine that the rule options are enclosed in a pair of parentheses and are also separated with semi-colons.
The first rule option, msg, which stands for message, provides the alert's text.
In this case, the alert will print out the text: "This is a message." There's also the option sid, which stands for signature ID.
This attaches a unique id to each signature.
The rev option stands for revision.
Each time a signature is updated or changed, the revision number changes.
Here, the number 1 means it's the first version of the signature.
Great!
Now you've developed another skill in your journey towards becoming a security analyst: how to read signatures.
There's so much more to learn and coming up, we'll discuss tools that use signatures.
Examine signatures with Suricata
Previously, you learned about signature-based analysis.
You also learned how to read signatures used in network-based intrusion detection systems.
Here, we'll use an open source signature-based IDS called Suricata to examine a signature.
Many NIDS technologies come with pre-written signatures.
You can think of these signatures as customizable templates.
Sort of like different templates available in a word processor.
These signature templates provide you with a starting point for writing and defining your rules.
You can also write and add your own rules.
Let's examine a pre-written signature through Suricata.
On this Linux machine running Ubuntu, Suricata is already installed.
Let's examine some of its files by changing directories to the etc directory and into the suricata directory.
This is where all of Suricata's configuration files live.
Next, we'll use the ls command to list the contents of the suricata directory.
There's a couple of different files in here, but we'll focus on the rules folder.
This is where the pre-written signatures are.
You can also add custom signatures here.
We'll use the cd command followed by the name of the folder to navigate to that folder.
Using the ls command, we can observe that the folder contains some rule templates for different protocols and services.
Let's examine the custom.rules file using the less command.
As a quick refresher, the less command returns the content of a file one page at a time which makes it easy to move forward and backward through the content.
We'll use the arrow key to scroll up.
Lines that begin with a pound sign (#) are comments meant to provide context for those who read them and are ignored by Suricata.
The first line says Custom rules example for HTTP connection.
This tells us that this file contains custom rules for HTTP connections.
We can observe that there's a signature.
The first word specifies the signature's ACTION.
For this signature, the action is alert.
This means that the signature generates an alert when all of the conditions are met.
The next part of the signature is the HEADER.
It specifies the protocol http.
The source IP address is HOME_NET and source port is defined as ANY.
The arrow indicates the direction of traffic coming from the home network and going to the destination IP address EXTERNAL_NET and ANY destination port.
So far, we know that this signature triggers an alert when it detects any HTTP traffic leaving the home network and going to the external network.
Let's examine the remainder of the signature to identify if there's any additional conditions the signature looks for.
The last part of the signature includes the RULE OPTIONS.
They're enclosed in parentheses and separated by semicolons.
There's many options listed here, but we'll focus on the message, flow, and content options.
The message option will show the message "GET on wire" once the alert is triggered.
The flow option is used to match on direction of network traffic flow.
Here, it's established.
This means that a connection has been successfully made.
The content option inspects the content of a packet.
Here, between the quotation marks, the text GET is specified.
GET is an HTTP request that's used to retrieve and request data from a server.
This means the signature will match if a network packet contains the text GET, indicating a request.
To summarize, this signature alerts anytime Suricata observes the text GET in an HTTP connection from the home network, going to the external network.
Every environment is different and in order for an IDS to be effective, signatures must be tested and tailored.
As a security analyst, you may test, modify, or create IDS signatures to improve the detection of threats in an environment and reduce the likelihood of false positives.
Coming up, we'll examine how Suricata logs events.
Meet you there.
Examine signatures with Suricata
Previously, you learned about signature-based analysis.
You also learned how to read signatures used in network-based intrusion detection systems.
Here, we'll use an open source signature-based IDS called Suricata to examine a signature.
Many NIDS technologies come with pre-written signatures.
You can think of these signatures as customizable templates.
Sort of like different templates available in a word processor.
These signature templates provide you with a starting point for writing and defining your rules.
You can also write and add your own rules.
Let's examine a pre-written signature through Suricata.
On this Linux machine running Ubuntu, Suricata is already installed.
Let's examine some of its files by changing directories to the etc directory and into the suricata directory.
This is where all of Suricata's configuration files live.
Next, we'll use the ls command to list the contents of the suricata directory.
There's a couple of different files in here, but we'll focus on the rules folder.
This is where the pre-written signatures are.
You can also add custom signatures here.
We'll use the cd command followed by the name of the folder to navigate to that folder.
Using the ls command, we can observe that the folder contains some rule templates for different protocols and services.
Let's examine the custom.rules file using the less command.
As a quick refresher, the less command returns the content of a file one page at a time which makes it easy to move forward and backward through the content.
We'll use the arrow key to scroll up.
Lines that begin with a pound sign (#) are comments meant to provide context for those who read them and are ignored by Suricata.
The first line says Custom rules example for HTTP connection.
This tells us that this file contains custom rules for HTTP connections.
We can observe that there's a signature.
The first word specifies the signature's ACTION.
For this signature, the action is alert.
This means that the signature generates an alert when all of the conditions are met.
The next part of the signature is the HEADER.
It specifies the protocol http.
The source IP address is HOME_NET and source port is defined as ANY.
The arrow indicates the direction of traffic coming from the home network and going to the destination IP address EXTERNAL_NET and ANY destination port.
So far, we know that this signature triggers an alert when it detects any HTTP traffic leaving the home network and going to the external network.
Let's examine the remainder of the signature to identify if there's any additional conditions the signature looks for.
The last part of the signature includes the RULE OPTIONS.
They're enclosed in parentheses and separated by semicolons.
There's many options listed here, but we'll focus on the message, flow, and content options.
The message option will show the message "GET on wire" once the alert is triggered.
The flow option is used to match on direction of network traffic flow.
Here, it's established.
This means that a connection has been successfully made.
The content option inspects the content of a packet.
Here, between the quotation marks, the text GET is specified.
GET is an HTTP request that's used to retrieve and request data from a server.
This means the signature will match if a network packet contains the text GET, indicating a request.
To summarize, this signature alerts anytime Suricata observes the text GET in an HTTP connection from the home network, going to the external network.
Every environment is different and in order for an IDS to be effective, signatures must be tested and tailored.
As a security analyst, you may test, modify, or create IDS signatures to improve the detection of threats in an environment and reduce the likelihood of false positives.
Coming up, we'll examine how Suricata logs events.
Meet you there.
Examine Suricata logs
Now let's examine some logs generated by Suricata.
In Suricata, alerts and events are output in a format known as EVE JSON.
EVE stands for Extensible Event Format and JSON stands for JavaScript Object Notation.
As you previously learned, JSON uses key-value pairs, which simplifies both searching and extracting text from log files.
Suricata generates two types of log data: alert logs and network telemetry logs.
Alert logs contain information that's relevant to security investigations.
Usually this is the output of signatures which have triggered an alert.
For example, a signature that detects suspicious traffic across the network generates an alert log that captures details of that traffic.
While network telemetry logs contain information about network traffic flows, network telemetry is not always security relevant, it's simply recording what's happening on a network, such as a connection being made to a specific port.
Both of these log types provide information to build a story during an investigation.
Let's examine an example of both log types.
Here's an example of an event log.
We can tell that this event is an alert because the event type field says alert.
There's also details about the activity that was logged including IP addresses and the protocol.
There are also details about the signature itself, such as the message and id.
From the signature's message, it appears that this alert relates to the detection of malware.
Next up, we have an example of a network telemetry log, which shows us the details of an http request to a website.
The event type field tells us it's an http log.
There's details about the request.
Under hostname, there's the website that was accessed.
The user agent is the name of software that connects you to the website.
In this case, it's the web browser Mozilla 5.0.
And the content type, which is the data the http request returned.
Here it's specified as HTML text.
That sums it up on the different types of log outputs.
In the upcoming activity, you'll be applying what we just explored by getting hands-on with Suricata.
Have fun!
Overview of Suricata
So far, you've learned about detection signatures and you were introduced to Suricata, an incident detection system (IDS).
In this reading, you’ll explore more about Suricata. You'll also learn about the value of writing customized signatures and configuration. This is an important skill to build in your cybersecurity career because you might be tasked with deploying and maintaining IDS tools.
Introduction to Suricata
is an open-source intrusion detection system, intrusion prevention system, and network analysis tool.
Suricata features
There are three main ways Suricata can be used:
-
Intrusion detection system (IDS): As a network-based IDS, Suricata can monitor network traffic and alert on suspicious activities and intrusions. Suricata can also be set up as a host-based IDS to monitor the system and network activities of a single host like a computer.
-
Intrusion prevention system (IPS): Suricata can also function as an intrusion prevention system (IPS) to detect and block malicious activity and traffic. Running Suricata in IPS mode requires additional configuration such as enabling IPS mode.
-
Network security monitoring (NSM): In this mode, Suricata helps keep networks safe by producing and saving relevant network logs. Suricata can analyze live network traffic, existing packet capture files, and create and save full or conditional packet captures. This can be useful for forensics, incident response, and for testing signatures. For example, you can trigger an alert and capture the live network traffic to generate traffic logs, which you can then analyze to refine detection signatures.
Rules
Rules or signatures are used to identify specific patterns, behavior, and conditions of network traffic that might indicate malicious activity. The terms rule and signature are often used interchangeably in Suricata. Security analysts use signatures, or patterns associated with malicious activity, to detect and alert on specific malicious activity. Rules can also be used to provide additional context and visibility into systems and networks, helping to identify potential security threats or vulnerabilities.
Suricata uses signatures analysis, which is a detection method used to find events of interest. Signatures consist of three components:
-
Action: The first component of a signature. It describes the action to take if network or system activity matches the signature. Examples include: alert, pass, drop, or reject.
-
Header: The header includes network traffic information like source and destination IP addresses, source and destination ports, protocol, and traffic direction.
-
Rule options: The rule options provide you with different options to customize signatures.
Here's an example of a Suricata signature:

Rule options have a specific ordering and changing their order would change the meaning of the rule.
Note: The terms rule and signature are synonymous.
Note: Rule order refers to the order in which rules are evaluated by Suricata. Rules are processed in the order in which they are defined in the configuration file. However, Suricata processes rules in a different default order: pass, drop, reject, and alert. Rule order affects the final verdict of a packet especially when conflicting actions such as a drop rule and an alert rule both match on the same packet.
Custom rules
Although Suricata comes with pre-written rules, it is highly recommended that you modify or customize the existing rules to meet your specific security requirements.
There is no one-size-fits-all approach to creating and modifying rules. This is because each organization's IT infrastructure differs. Security teams must extensively test and modify detection signatures according to their needs.
Creating custom rules helps to tailor detection and monitoring. Custom rules help to minimize the amount of false positive alerts that security teams receive. It's important to develop the ability to write effective and customized signatures so that you can fully leverage the power of detection technologies.
Configuration file
Before detection tools are deployed and can begin monitoring systems and networks, you must properly configure their settings so that they know what to do. A configuration file is a file used to configure the settings of an application. Configuration files let you customize exactly how you want your IDS to interact with the rest of your environment.
Suricata's configuration file is suricata.yaml, which uses the YAML file format for syntax and structure.
Log files
There are two log files that Suricata generates when alerts are triggered:
-
eve.json: The eve.json file is the standard Suricata log file. This file contains detailed information and metadata about the events and alerts generated by Suricata stored in JSON format. For example, events in this file contain a unique identifier called flow_id which is used to correlate related logs or alerts to a single network flow, making it easier to analyze network traffic. The eve.json file is used for more detailed analysis and is considered to be a better file format for log parsing and SIEM log ingestion.
-
fast.log: The fast.log file is used to record minimal alert information including basic IP address and port details about the network traffic. The fast.log file is used for basic logging and alerting and is considered a legacy file format and is not suitable for incident response or threat hunting tasks.
The main difference between the eve.json file and the fast.log file is the level of detail that is recorded in each. The fast.log file records basic information, whereas the eve.json file contains additional verbose information.
Key takeaways
In this reading, you explored some of Suricata's features, rules syntax, and the importance of configuration. Understanding how to configure detection technologies and write effective rules will provide you with clear insight into the activity happening in an environment so that you can improve detection capability and network visibility. Go ahead and start practicing using Suricata in the upcoming activity!
Resources for more information
If you would like to learn more about Suricata including rule management and performance, check out the following resources:
Activity: Explore signatures and logs with Suricata
Introduction
In this lab activity, you'll explore the components of a rule using Suricata. You'll also have an opportunity to trigger a rule and examine the output in Suricata. You'll use the Bash shell to complete these steps.
What you’ll do
You have multiple tasks in this lab:
-
Examine a rule in Suricata
-
Trigger a rule and review the alert logs
-
Examine eve.json outputs
Lab instructions
i could setup a lab 4 u if u email inquiries@naruzkurai.com or Inquiries@baseshadow.maskmy.id
Reexamine SIEM tools
As a security analyst, you'll need to be able to quickly access the relevant data required to perform your duties.
Whether it's triaging alerts, monitoring systems, or analyzing log data during incident investigations, a SIEM is the tool for this job.
As a quick review, a SIEM is an application that collects and analyzes log data to monitor critical activities in an organization.
It does this by collecting, analyzing, and reporting on security data from multiple sources.
Previously, you learned about the SIEM process for data collection.
Let's revisit this process.
First, SIEM tools COLLECT AND PROCESS enormous amounts of data generated by devices and systems from all over an environment.
Not all data is the same.
As you already know, devices generate data in different formats.
This can be challenging because there is no unified format to represent the data.
SIEM tools make it easy for security analysts to read and analyze data by NORMALIZING it.
Raw data gets processed, so that it's formatted consistently and only relevant event information is included.
Finally, SIEM tools INDEX the data, so it can be accessed through search.
All of the events across all the different sources can be accessed with your fingertips.
Isn't that useful?
SIEM tools make it easy to quickly access and analyze the data flows happening across networks in an environment.
As a security analyst, you may encounter different SIEM tools.
It's important that you're able to adjust and adapt to whichever tool your organization ends up using.
With that in mind, let's explore some SIEM tools currently used in the security industry.
Splunk is a data analysis platform.
Splunk Enterprise Security provides SIEM solutions that let you search, analyze, and visualize security data.
First, it collects data from different sources.
That data gets processed and stored in an index.
Then, it can be accessed in a variety of different ways, like through search.
Chronicle is Google Cloud's SIEM, which stores security data for search, analysis, and visualization.
First, data gets forwarded to Chronicle.
This data then gets normalized, or cleaned up, so it's easier to process and index.
Finally, the data becomes available to be accessed through a search bar.
Next up, we'll explore how to search on these SIEM platforms.
Log sources and log ingestion
In this reading, you’ll explore more on the importance of log ingestion. You may recall that security information and event management (SIEM) tools collect and analyze log data to monitor critical activities in an organization. You also learned about log analysis, which is the process of examining logs to identify events of interest. Understanding how log sources are ingested into SIEM tools is important because it helps security analysts understand the types of data that are being collected, and can help analysts identify and prioritize security incidents.
SIEM process overview
Previously, you covered the SIEM process. As a refresher, the process consists of three steps:
-
Collect and aggregate data: SIEM tools collect event data from various data sources.
-
Normalize data: Event data that's been collected becomes normalized. Normalization converts data into a standard format so that data is structured in a consistent way and becomes easier to read and search. While data normalization is a common feature in many SIEM tools, it's important to note that SIEM tools vary in their data normalization capabilities.
-
Analyze data: After the data is collected and normalized, SIEM tools analyze and correlate the data to identify common patterns that indicate unusual activity.
This reading focuses on the first step of this process, the collection and aggregation of data.
Log ingestion

Data is required for SIEM tools to work effectively. SIEM tools must first collect data using log ingestion. Log ingestion is the process of collecting and importing data from log sources into a SIEM tool. Data comes from any source that generates log data, like a server.
In log ingestion, the SIEM creates a copy of the event data it receives and retains it within its own storage. This copy allows the SIEM to analyze and process the data without directly modifying the original source logs. The collection of event data provides a centralized platform for security analysts to analyze the data and respond to incidents. This event data includes authentication attempts, network activity, and more.
Log forwarders
There are many ways SIEM tools can ingest log data. For instance, you can manually upload data or use software to help collect data for log ingestion. Manually uploading data may be inefficient and time-consuming because networks can contain thousands of systems and devices. Hence, it's easier to use software that helps collect data.
A common way that organizations collect log data is to use log forwarders. Log forwarders are software that automate the process of collecting and sending log data. Some operating systems have native log forwarders. If you are using an operating system that does not have a native log forwarder, you would need to install a third-party log forwarding software on a device. After installing it, you'd configure the software to specify which logs to forward and where to send them. For example, you can configure the logs to be sent to a SIEM tool. The SIEM tool would then process and normalize the data. This allows the data to be easily searched, explored, correlated, and analyzed.
Note: Many SIEM tools utilize their own proprietary log forwarders. SIEM tools can also integrate with open-source log forwarders. Choosing the right log forwarder depends on many factors such as the specific requirements of your system or organization, compatibility with your existing infrastructure, and more.
Key takeaways
SIEM tools require data to be effective. As a security analyst, you will utilize SIEM tools to access events and analyze logs when you're investigating an incident. In your security career, you may even be tasked with configuring a SIEM to collect log data. It's important that you understand how data is ingested into SIEM tools because this enables you to understand where log sources come from which can help you identify the source of a security incident.
Resources
Here are some resources if you’d like to learn more about the log ingestion process for Splunk and Chronicle:
Query for events with Splunk
Now that we've reviewed how a SIEM works, let's learn how to search and query events in a SIEM database.
Data that's been imported into a SIEM can be accessed by entering queries into the SIEM's search engine.
Massive amounts of data can be stored in a SIEM database.
Some of this data may date back years.
This can make searching for security events challenging.
For example, let's say you're searching to find a failed login event.
You search for the event using the keywords: failed login.
This is a very broad query, which can return thousands of results.
Broad search queries like this, slow down the response times of a search engine since it's searching across all the indexed data.
But, if you specify additional parameters, like an event ID and a date and time range, you can narrow down the search to get faster results.
It's important that search queries are specific, so that you can find exactly what you're looking for and save time in the search process.
Different SIEM tools use different search methods.
For example, Splunk uses its own query language called Search Processing Language, or SPL for short.
SPL has many different search options you can use to optimize search results, so that you can get the data you're looking for.
For now, I'll demonstrate a raw log search in Splunk Cloud for events that reference errors or failures for a fictional online store called Buttercup Games.
First, we'll use the search bar to type in our query: buttercupgames error OR fail* This search is specifying the index, which is buttercupgames.
We also specify the search terms: error OR fail.
The Boolean operator OR ensures that both of the keywords will be searched.
The asterisk at the end of the term fail* is known as a wildcard.
This means it will search for all possible endings that contain the term fail.
This helps us expand our search results because events may label failures differently.
For example, some events may use the term failed.
Next, we'll select a time range using the time range picker.
Remember, the more specific our search is, the better.
Let's search for data from the last 30 days.
Under the search bar, we have our search results.
There's a timeline, which gives us a visual representation of the number of events over a period.
This can be helpful in identifying event patterns such as peaks in activity.
Under the timeline, there's the events viewer, which gives us a list of events that match our search.
Notice how our search terms: buttercupgames and error are highlighted in each event.
It doesn't appear that any events matching with the term fail were found.
Each event has a timestamp and raw logged data.
For the events with errors, it appears that there's an error relating to the HTTP cookies used in the Buttercup Games website.
At the bottom of the raw log data, there's some information related to the data source, including the host name, source, and source type.
This information tells us where the event data originated from such as a device or file.
If we click on it, we can choose to exclude it from the search results.
On the search bar, we can examine that the search terms have been changed and host!=www1 has been added, which means not to include www1 hosts.
Notice that the new search results do not contain www1 as a host, but contain www2 and www3.
This is just one of the many ways that you can target your searches to retrieve information you're looking for.
This search is known as a raw log search.
As a security analyst, you'll use different commands to optimize search performance for faster search results.
That completes querying in Splunk.
You've learned the importance of effective queries and how to perform a basic Splunk search.
Coming up, you'll learn how to query events in Chronicle.
Search methods with SIEM tools
So far, you’ve learned about how you can use security information and event management (SIEM) tools to search for security events such as failed login attempts. Remember, SIEM is an application that collects and analyzes log data to monitor critical activities in an organization. In this reading, you’ll examine how SIEM tools like Splunk and Chronicle use different search methods to find, filter, and transform search results.
Not all organizations use the same SIEM tool to gather and centralize their security data. As a security analyst, you’ll need to be ready to learn how to use different SIEM tools. It’s important to understand the different types of searches you can perform using SIEM tools so that you can find relevant event data to support your security investigations.
Splunk searches
As you’ve learned, Splunk has its own querying language called Search Processing Language (SPL). SPL is used to search and retrieve events from indexes using Splunk’s Search & Reporting app. An SPL search can contain many different commands and arguments. For example, you can use commands to transform your search results into a chart format or filter results for specific information.

Here is an example of a basic SPL search that is querying an index for a failed event:
index=main fail
-
index=main: This is the beginning of the search command that tells Splunk to retrieve events from an index named main. An index stores event data that's been collected and processed by Splunk.
-
fail: This is the search term. This tells Splunk to return any event that contains the term fail.
Knowing how to effectively use SPL has many benefits. It helps shorten the time it takes to return search results. It also helps you obtain the exact results you need from various data sources. SPL supports many different types of searches that are beyond the scope of this reading. If you would like to learn more about SPL, explore Splunk's Search Reference
.
Pipes
Previously, you might have learned about how piping is used in the Linux bash shell. As a refresher, piping sends the output of one command as the input to another command.
SPL also uses the pipe character | to separate the individual commands in the search. It's also used to chain commands together so that the output of one command combines into the next command. This is useful because you can refine data in various ways to get the results you need using a single command.
Here is an example of two commands that are piped together:
index=main fail| chart count by host
-
index=main fail: This is the beginning of the search command that tells Splunk to retrieve events from an index named main for events containing the search term fail.
-
|: The pipe character separates and chains the two commands index=main and chart count by host. This means that the output of the first command index=main is used as the input of the second command chart count by host.
-
chart count by host: This command tells Splunk to transform the search results by creating a chart according to the count or number of events. The argument by host tells Splunk to list the events by host, which are the names of the devices the events come from. This command can be helpful in identifying hosts with excessive failure counts in an environment.
Wildcard
A wildcard is a special character that can be substituted with any other character. A wildcard is usually symbolized by an asterisk character *. Wildcards match characters in string values. In Splunk, the wildcard that you use depends on the command that you are using the wildcard with. Wildcards are useful because they can help find events that contain data that is similar but not entirely identical. Here is an example of using a wildcard to expand the search results for a search term:
index=main fail*
-
index=main: This command retrieves events from an index named main.
-
fail*: The wildcard after fail represents any character. This tells Splunk to search for all possible endings that contain the term fail. This expands the search results to return any event that contains the term fail such as “failed” or “failure”.
Pro tip: Double quotations are used to specify a search for an exact phrase or string. For example, if you want to only search for events that contain the exact phrase login failure, you can enclose the phrase in double quotations "login failure". This search will match only events that contain the exact phrase login failure and not other events that contain the words failure or login separately.
Chronicle searches
In Chronicle, you can search for events using the Search field. You can also use Procedural Filtering to apply filters to a search to further refine the search results. For example, you can use Procedural Filtering to include or exclude search results that contain specific information relating to an event type or log source. There are two types of searches you can perform to find events in Chronicle, a Unified Data Mode (UDM) Search or a Raw Log Search.

Unified Data Model (UDM) Search
The UDM Search is the default search type used in Chronicle. You can perform a UDM search by typing your search, clicking on “Search,” and selecting “UDM Search.” Through a UDM Search, Chronicle searches security data that has been ingested, parsed, and normalized. A UDM Search retrieves search results faster than a Raw Log Search because it searches through indexed and structured data that’s normalized in UDM.

A UDM Search retrieves events formatted in UDM and these events contain UDM fields. There are many different types of UDM fields that can be used to query for specific information from an event. Discussing all of these UDM fields is beyond the scope of this reading, but you can learn more about UDM fields by exploring Chronicle's UDM field list
. Know that all UDM events contain a set of common fields including:
-
Entities: Entities are also known as nouns. All UDM events must contain at least one entity. This field provides additional context about a device, user, or process that’s involved in an event. For example, a UDM event that contains entity information includes the details of the origin of an event such as the hostname, the username, and IP address of the event.
-
Event metadata: This field provides a basic description of an event, including what type of event it is, timestamps, and more.
-
Network metadata: This field provides information about network-related events and protocol details.
-
Security results: This field provides the security-related outcome of events. An example of a security result can be an antivirus software detecting and quarantining a malicious file by reporting "virus detected and quarantined."
Here’s an example of a simple UDM search that uses the event metadata field to locate events relating to user logins:
metadata.event_type = “USER_LOGIN”
-
metadata.event_type = “USER_LOGIN”: This UDM field metadata.event_type contains information about the event type. This includes information like timestamp, network connection, user authentication, and more. Here, the event type specifies USER_LOGIN, which searches for events relating to authentication.
Using just the metadata fields, you can quickly start searching for events. As you continue practicing searching in Chronicle using UDM Search, you will encounter more fields. Try using these fields to form specific searches to locate different events.
Raw Log Search
If you can't find the information you are searching for through the normalized data, using a Raw Log Search will search through the raw, unparsed logs. You can perform a Raw Log Search by typing your search, clicking on “Search,” and selecting “Raw Log Search.” Because it is searching through raw logs, it takes longer than a structured search. In the Search field, you can perform a Raw Log Search by specifying information like usernames, filenames, hashes, and more. Chronicle will retrieve events that are associated with the search.
Pro tip: Raw Log Search supports the use of regular expressions, which can help you narrow down a search to match on specific patterns.
Key takeaways
SIEM tools like Splunk and Chronicle have their own methods for searching and retrieving event data. As a security analyst, it's important to understand how to leverage these tools to quickly and efficiently find the information you need. This will allow you to explore data in ways that support detecting threats, as well as rapidly responding to security incidents.
Resources for more information
Here are some resources should you like to learn more about searching for events with Splunk and Chronicle:
-
on how to use the Splunk search processing language (SPL)
-
on the different types of searches
Follow-along guide for Splunk sign-up
Note: The following reading is an optional supplement to the following course item, Activity: Perform a query with Splunk
. Both this reading and the following activity are optional and will not affect your completion of the course. You may choose to skip this reading and/or the activity for any reason, and continue progressing through the remainder of the course.
This reading includes detailed instructions for getting started with the following course item, Activity: Perform a query with Splunk
. Use this reading for step-by-step instructions on how to create a Splunk Cloud account, activate a Splunk Cloud free trial, and upload data to a Splunk Cloud instance.
The following guide identifies parts of the video that may require adjustment. This reference guide can also serve as a usability reminder when using Splunk Cloud in the future.
Instructions
Part 1 - Create a Splunk Cloud account
-
Go to the Splunk Cloud Platform Trial
-
page.
-
Fill in the fields in the Start Your Cloud Platform Trial sign-up form.
-
Click Create Your Account.



Part 2 - Verify your email
1. Check the inbox for the email address that you used to sign up for the Splunk account. Find the verification email from Splunk with the subject line Confirm your email address.

2. Open the email and click the Verify Your Email button.

Note: Check your spam folder if you didn't receive the verification email.
Part 3 - Activate a Splunk Cloud trial
After clicking the Verify Your Email button, you'll be redirected to the Splunk Cloud Trial page.
Note: You can activate one Splunk Cloud trial instance at a time, and you can use a maximum of three trials per Splunk account. The Splunk Cloud free trial expires after 14 days, so you may want to complete this activity before the free trial expires.
Note: Alternatively, you can also access the Splunk Cloud Trial page by visiting Splunk Cloud Platform Trial
and logging into your account, then clicking Start Trial.
1. Click the Start Trial button.


2. Check your inbox for an email from Team Splunk with the subject line Welcome to Splunk Cloud Platform!

3. Open the email to access your Splunk Cloud login information.
4. Click the link beside URL to access the Splunk Cloud Platform.

5. Enter the username and password credentials that were included in the email.

6. You will be prompted to change the password of the Splunk Cloud Platform account. Enter a new password and click Save Password.

7. Check the box next to I accept these terms and click Ok.

Part 4 - Download and upload Splunk data
After you've accepted the Terms of Service, you'll automatically be redirected to the Splunk Home dashboard.
1. Go to Activity: Perform a query with Splunk
.
2. Go to Step 1: Access supporting materials.

3. Beside Link to supporting materials click tutorialdata.zip
.
4. Click the download icon to download the zip file.

5. Go to the Splunk Home dashboard.
6. On the Splunk bar, click Settings and then click Add Data.


7. Click Upload.
8. Click Select File to upload the tutorialdata.zip file. Alternatively, you can also drag and drop your file in the Drop your data file here box.

9. Once the file is uploaded, click Next to continue to Input Settings.

10. By the Host section, select Segment in path and enter 1 as the segment number.

11. Click Review and check the details of the upload before you submit. The details should be as follows:
-
Input Type: Uploaded File
-
File Name: tutorialdata.zip
-
Source Type: Automatic
-
Host: Source path segment number: 1
-
Index: Default
12. After you've verified that the details are correct, click Submit.

13. Once Splunk has ingested the data, you will receive a confirmation message stating that the file has been uploaded successfully.

14. Click the Splunk Cloud logo to return to the home page.
You're done! Once your Splunk Cloud account is set up, you can begin the next course item, Activity: Perform a query with Splunk
.
Need additional help? If you are experiencing any issues with your Splunk Cloud account, please contact Splunk's Help Center
. Remember, the following course item, Activity: Perform a query with Splunk, is optional and will not affect your completion of the course. If you are not able to create and set up a Splunk Cloud account, you can skip the activity.
Wrap-up; Glossary terms from module 4
Congratulations!
You've made it to the end of this section.
You've made so much progress in your security journey.
Let's review what we learned.
You learned all about how to read and analyze logs.
You examined how log files are created and used for analysis.
You also compared different types of common log formats and learned how to read them.
You extended your understanding on intrusion detection systems by comparing network-based systems and host-based systems.
You also learned how to interpret signatures.
You examined how signatures are written and also how they detect, log, and alert on intrusions.
You interacted with Suricata in the command line to examine and interpret signatures and alerts.
Lastly, you learned how to search in SIEM tools like Splunk and Chronicle.
You learned about the importance of crafting tailored queries to locate events.
At the forefront of incident response, monitoring and analyzing network traffic for indicators of compromise is one of the primary goals.
Being able to perform in-depth log analysis and knowing how to read and write signatures and how to access log data are all skills that you'll use as a security analyst.
Terms and definitions from Course 6, Module 4
Anomaly-based analysis: A detection method that identifies abnormal behavior
Array: A data type that stores data in a comma-separated ordered list
Common Event Format (CEF): A log format that uses key-value pairs to structure data and identify fields and their corresponding values
Configuration file: A file used to configure the settings of an application
Endpoint: Any device connected on a network
Endpoint detection and response (EDR): An application that monitors an endpoint for malicious activity
False positive: An alert that incorrectly detects the presence of a threat
Host-based intrusion detection system (HIDS): An application that monitors the activity of the host on which it’s installed
Intrusion detection systems (IDS): An application that monitors system activity and alerts on possible intrusions
Key-value pair: A set of data that represents two linked items: a key, and its corresponding value
Log: A record of events that occur within an organization’s systems
Log analysis: The process of examining logs to identify events of interest
Log management: The process of collecting, storing, analyzing, and disposing of log data
Logging: The recording of events occurring on computer systems and networks
Network-based intrusion detection system (NIDS): An application that collects and monitors network traffic and network data
Object: A data type that stores data in a comma-separated list of key-value pairs
Search Processing Language (SPL): Splunk’s query language
Security information and event management (SIEM): An application that collects and analyzes log data to monitor critical activities in an organization
Signature: A pattern that is associated with malicious activity
Signature analysis: A detection method used to find events interest
Suricata: An open-source intrusion detection system, intrusion prevention system, and network analysis tool
Telemetry: The collection and transmission of data for analysis
Wildcard: A special character that can be substituted with any other character
YARA-L: A computer language used to create rules for searching through ingested log data
Zero-day: An exploit that was previously unknown
Course wrap-up
Congratulations on completing this course on detection and response!
As you've progressed, we've covered a wide range of topics and tools.
Let's take a moment to review what you've learned.
First, we began with an overview of the incident response lifecycle.
You learned how security teams coordinate their response efforts.
And you explored the documentation, detection, and management tools used in incident response.
Next, you learned how to monitor and analyze network traffic.
You learned about capturing and analyzing packets using packets sniffers.
You also practiced using tools like tcpdump to capture and analyze network data to identify indicators of compromise.
Then, we explored processes and procedures involved in the phases of the incident response lifecycle.
You learned about techniques related to incident detection and analysis.
You also learned about documentation like chain of custody, playbooks, and final reports.
We ended with exploring strategies used for recovery and post-incident activity.
Finally, you learned how to interpret logs and alerts.
You explored Suricata on the command line to read and understand signatures and rules.
You also used SIEM tools like Splunk and Chronicle to search for events and logs.
As a security analyst, you'll be presented with a new challenge every day.
Whether it's investigating evidence or documenting your work, you'll use what you've learned in this course to effectively respond to incidents.
I'm so glad to have been on this learning journey with you.
You've done a fantastic job in expanding your knowledge and learning new tools to add to your security toolbox.
One of the things I love about the security field is that there's always something new to learn.
And coming up, you'll continue your learning journey by exploring a programming language called Python, which can be used to automate security tasks.
Keep up the great work!
Terms and definitions from Course 6, course 6 glossary
A
Advanced persistent threat (APT): An instance when a threat actor maintains unauthorized access to a system for an extended period of time
Analysis: The investigation and validation of alerts
Anomaly-based analysis: A detection method that identifies abnormal behavior
Array: A data type that stores data in a comma-separated ordered list
B
Broken chain of custody: Inconsistencies in the collection and logging of evidence in the chain of custody
Business continuity plan (BCP): A document that outlines the procedures to sustain business operations during and after a significant disruption
C
Chain of custody: The process of documenting evidence possession and control during an incident lifecycle
Command and control (C2): The techniques used by malicious actors to maintain communications with compromised systems
Command-line interface (CLI): A text-based user interface that uses commands to interact with the computer
Common Event Format (CEF): A log format that uses key-value pairs to structure data and identify fields and their corresponding values
Computer security incident response teams (CSIRT): A specialized group of security professionals that are trained in incident management and response
Configuration file: A file used to configure the settings of an application
Containment: The act of limiting and preventing additional damage caused by an incident
Crowdsourcing: The practice of gathering information using public collaboration
D
Data exfiltration: Unauthorized transmission of data from a system
Data packet: A basic unit of information that travels from one device to another within a network
Detection: The prompt discovery of security events
Documentation: Any form of recorded content that is used for a specific purpose
E
Endpoint: Any device connected on a network
Endpoint detection and response (EDR): An application that monitors an endpoint for malicious activity
Eradication: The complete removal of the incident elements from all affected systems
Event: An observable occurrence on a network, system, or device
F
False negative: A state where the presence of a threat is not detected
False positive: An alert that incorrectly detects the presence of a threat
Final report: Documentation that provides a comprehensive review of an incident
H
Honeypot: A system or resource created as a decoy vulnerable to attacks with the purpose of attracting potential intruders
Host-based intrusion detection system (HIDS): An application that monitors the activity of the host on which it’s installed
I
Incident: An occurrence that actually or imminently jeopardizes, without lawful authority, the confidentiality, integrity, or availability of information or an information system; or constitutes a violation or imminent threat of violation of law, security policies, security procedures, or acceptable use policies
Incident handler’s journal: A form of documentation used in incident response
Incident response plan: A document that outlines the procedures to take in each step of incident response
Indicators of attack (IoA): The series of observed events that indicate a real-time incident
Indicators of compromise (IoC): Observable evidence that suggests signs of a potential security incident
Internet Protocol (IP): A set of standards used for routing and addressing data packets as they travel between devices on a network
Intrusion detection system (IDS): An application that monitors system activity and alerts on possible intrusions
Intrusion prevention system (IPS): An application that monitors system activity for intrusive activity and takes action to stop the activity
K
Key-value pair: A set of data that represents two linked items: a key, and its corresponding value
L
Lessons learned meeting: A meeting that includes all involved parties after a major incident
Log analysis: The process of examining logs to identify events of interest
Log management: The process of collecting, storing, analyzing, and disposing of log data
Logging: The recording of events occurring on computer systems and networks
M
Media Access Control (MAC) Address: A unique alphanumeric identifier that is assigned to each physical device on a network
N
National Institute of Standards and Technology (NIST) Incident Response Lifecycle: A framework for incident response consisting of four phases: Preparation; Detection and Analysis; Containment, Eradication, and Recovery; and Post-incident activity
Network-based intrusion detection system (NIDS): An application that collects and monitors network traffic and network data
Network data: The data that’s transmitted between devices on a network
Network Interface Card (NIC): Hardware that connects computers to a network
Network protocol analyzer (packet sniffer): A tool designed to capture and analyze data traffic within a network
Network traffic: The amount of data that moves across a network
O
Object: A data type that stores data in a comma-separated list of key-value pairs
Open-source intelligence (OSINT): The collection and analysis of information from publicly available sources to generate usable intelligence
P
Packet capture (p-cap): A file containing data packets intercepted from an interface or network
Packet sniffing: The practice of capturing and inspecting data packets across a network
Playbook: A manual that provides details about any operational action
Post-incident activity: The process of reviewing an incident to identify areas for improvement during incident handling
R
Recovery: The process of returning affected systems back to normal operations
Resilience: The ability to prepare for, respond to, and recover from disruptions
Root user (or superuser): A user with elevated privileges to modify the system
S
Search Processing Language (SPL): Splunk’s query language
Security information and event management (SIEM): An application that collects and analyzes log data to monitor critical activities in an organization
Security operations center (SOC): An organizational unit dedicated to monitoring networks, systems, and devices for security threats or attacks
Security orchestration, automation, and response (SOAR): A collection of applications, tools, and workflows that uses automation to respond to security events
Signature: A pattern that is associated with malicious activity
Signature analysis: A detection method used to find events interest
Standards: References that inform how to set policies
Sudo: A command that temporarily grants elevated permissions to specific users
Suricata: An open-source intrusion detection system and intrusion prevention system
T
tcpdump: A command-line network protocol analyzer
Telemetry: The collection and transmission of data for analysis
Threat hunting: The proactive search for threats on a network
Threat intelligence: Evidence-based threat information that provides context about existing or emerging threats
Triage: The prioritizing of incidents according to their level of importance or urgency
True negative: A state where there is no detection of malicious activity
True positive An alert that correctly detects the presence of an attack
V
VirusTotal: A service that allows anyone to analyze suspicious files, domains, URLs, and IP addresses for malicious content
W
Wildcard: A special character that can be substituted with any other character
Wireshark: An open-source network protocol analyzer
Y
YARA-L: A computer language used to create rules for searching through ingested log data
Zero-day: An exploit that was previously unknown